
Last year, Notion launched data residency for EU customers. Delivering this was a complex, multi-stage, multi-team effort that encountered many challenging problems and uncovered several valuable learnings.
While data residency benefits every part of Notion, this post focuses on how it applies to our data systems. Data is often associated with backend analytics: Think dashboards, reports, or business intelligence. Notion's data systems also power product features that people use every day—like Search, Enterprise Audit Logs, Workspace and Page Analytics, scheduled events, and Notion AI. Much of this involves customer data, so it's important that the systems honor residency across different regions.
What Data Residency Means in Practice
The key principle of data residency is straightforward: Data is processed and stored in the region where it was generated. From the moment customer data enters our systems, it never leaves its home region’s infrastructure, whether it’s indexed for search, processed for analytics, or transformed into embeddings for AI features. This is most critical when supporting the compliance and privacy requirements of our EU customers.
Data residency isn't a single pipeline or configuration change, nor is it just a matter of copy-pasting our environment into a new region. Some components were set up per region, like distinct Apache Spark jobs, Vector Databases for storing AI embeddings, and storage layers. But there were also many changes to our existing systems and new supporting infrastructure, to make our systems region-aware without the unwanted flow of data between regions.
Preparing for Data Residency
To prepare Notion’s overall infrastructure to span regions, it was first redesigned to be more modular and agile. Projects were refactored to prevent unnecessary code or service dependencies. Systems were split up into isolated private networks, where each processes a slice of the application data with minimal cross-communication. This helps Notion provision standardized resources as our business needs evolve.
A key property behind this isolation is that all of the processing and storage for a given Notion workspace happens within the same network. This enables us to use the workspace ID as the primary routing and partitioning identifier.
This modularization didn’t just make it easier to scale; it also laid the foundation for multi-region support across all of Notion. These two goals are deeply connected: building systems that scale flexibly also enables hosting data and workloads across multiple regions with consistent patterns. If you have multiple isolated networks, then their data flows are similar whether they are in the same or different regions.
Here's a look at a few of these areas at a high level to show the kind of work that went into enabling data residency behind the scenes.
A Glimpse into How Data Residency Works at Notion
Bringing data residency to Notion also required broader work across the platform. That included optimizing cloud resource usage across regions and ensuring low latency, so EU customers don’t experience Notion as a second-class product. Regardless of where a workspace lives, Notion should feel like a single, cohesive experience.
While those efforts span many layers of the stack, the sections that follow focus on the data components that make region-local processing possible. These examples don’t capture every part of Notion’s data residency work, but they illustrate how we approach the problem.
Regional Data Lake
Notion relies on a data lake to power analytics and product features such as Search and AI. To support data residency, we separated this data lake by region.
For EU customers, workspace data is stored in EU-based databases. To make that data usable downstream, we built region-specific ingestion pipelines that process changes entirely within that region’s infrastructure.
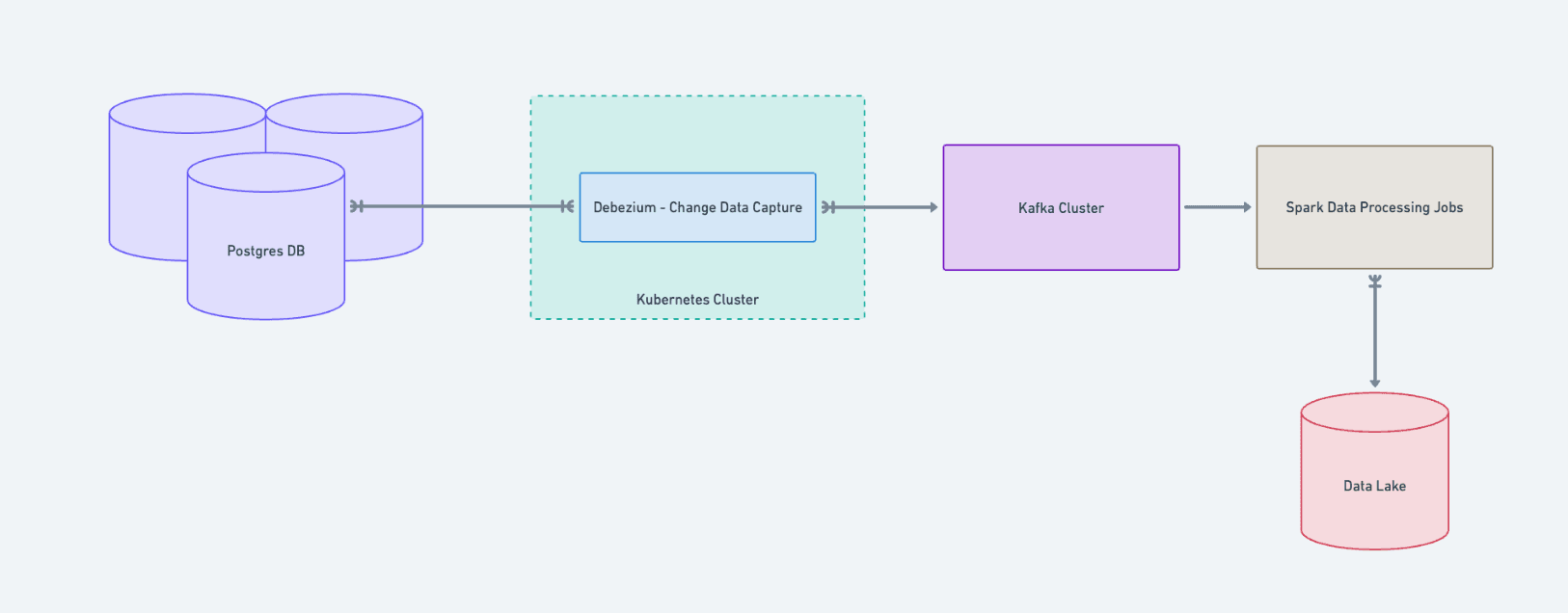
These pipelines use change data capture (via Debezium running in Kubernetes) to stream updates from Postgres into Kafka. From there, Spark jobs transform the data and write it into the regional data lake. Downstream systems can operate on up-to-date data without it ever leaving its home region.
Product features only read from the data lake in their region. For example, Search for EU workspaces is powered by a dedicated Elasticsearch cluster that builds its indices exclusively from EU data.
This structure helps enable data-powered features while maintaining clear, enforceable regional boundaries.
Regional AI Infrastructure
Notion’s AI features rely on a regional indexing pipeline that prepares workspace content for use in AI-powered experiences. As with other data systems, this infrastructure respects data residency boundaries.
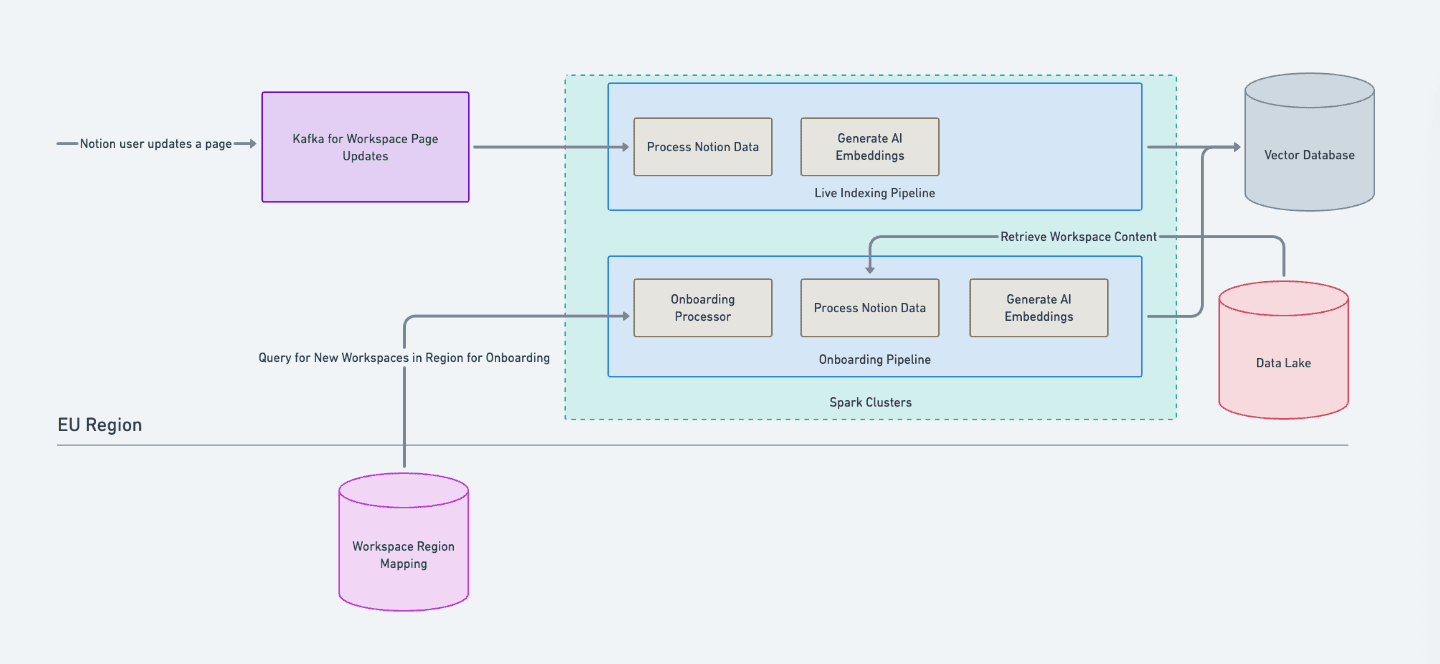
When a workspace becomes eligible for AI, an onboarding process embeds its existing content and stores those embeddings in a regional vector database. Because onboarding requires coordinating workspace metadata and determining where data should be processed, we rely on a centralized mapping table that acts as the source of truth for each workspace's active region. This ensures onboarding runs only in the correct regional environment.
After onboarding, updates to workspace content are written to a regional Kafka cluster. From there, Spark jobs process those changes, generate updated embeddings, and write them back to the regional vector database, keeping AI results current without data leaving its home region.
By making region a first-class input to our AI onboarding and update workflows, we ensure that AI features operate only on local data while remaining consistent and reliable as workspaces evolve.
Job Orchestration System
We use Apache Airflow to orchestrate the jobs that power our systems, such as those highlighted above. Our main instance is located in a US datacenter, and we decided not to change this as part of data residency because it doesn't process any customer data directly—we have region-specific EMR clusters that run Spark jobs for that purpose. Airflow acts purely as an orchestrator to send requests to the data's region, which allowed us to keep a simple scheduling control plane.
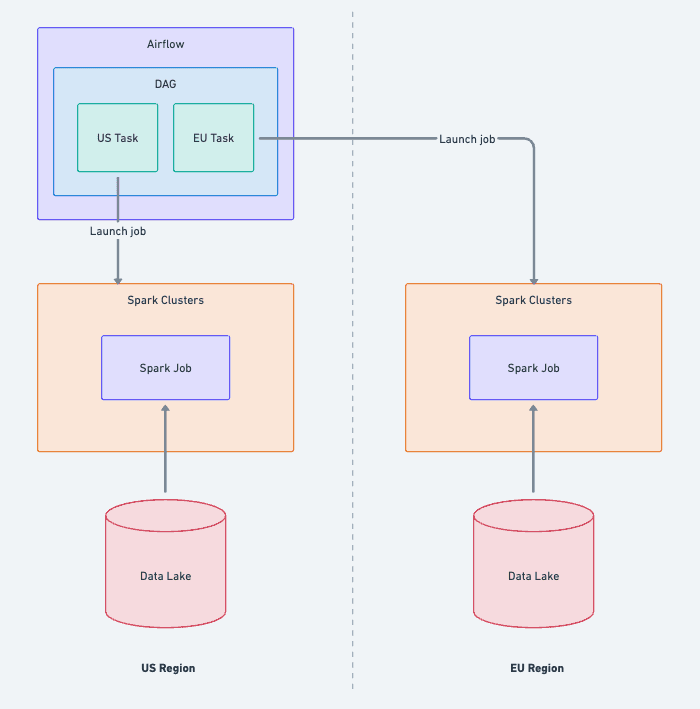
Several changes were required to maintain this centralization. Our Spark Airflow operators now all require regional information, and mapping tables use that to determine which cluster to run the job on and which S3 buckets to use. We updated our relevant DAGs to loop through both US and EU regions, which created region-specific tasks that we could monitor on the same screen.
Event Logging
Client and server code in the Notion application generates event logs, which make their way to our centralized data warehouse for analysis. Some features, such as workspace analytics, depend on these events being received and processed regionally. We achieve this in different ways depending up on the source.
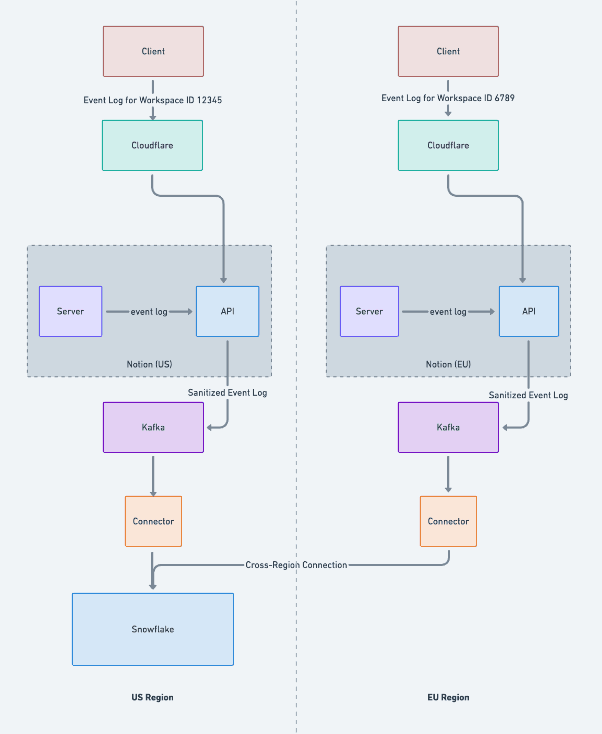
Client calls to our event API endpoints include an HTTP header that indicates the workspace ID. This passes through Cloudflare, where space-aware workers direct the traffic to a server in the appropriate region and network. By contrast, server events are always generated in the correct network, because data residency ensures that's where the workspace data is processed. So the server simply writes to its local load balancer, which forwards the request to a local API server.
The logging API endpoint sanitizes the events it receives to ensure they don't contain any customer data that developers may have accidentally included. It writes the events to a regional Apache Kafka cluster, and then sinks the data to a region-specific Snowflake table. A downstream view merges the events from the different regions.
When we first set up our event logging pipeline in 2022, we used a single-region Flink job that read from Apache Kafka and stored its output on S3, then a Snowflake Snowpipe would import new data that it detected in the bucket. This approach gave us full control over the ETL pipeline, but nowadays many managed solutions offer the same functionality. So we chose this opportunity to simplify the design via a Snowpipe streaming connector in each region that pushes directly to Snowflake.
Designing for Maintainability
Maintainability for Engineering
All of our infrastructure is managed with Terraform, which helps standardize environments and ensure consistency across regions. That said, adding new infrastructure can still be disruptive because it increases complexity and broadens the blast radius of changes. The more infrastructure we manage, the more important it becomes to keep things organized, discoverable, and easy to maintain over time.
Here are a few patterns we use to keep our systems maintainable:
Mapping table
We maintain a centralized table that maps each workspace to its active region.
This helps identify where a workspace's data is stored and becomes especially important when a workspace goes through a data migration across regions.
Code helpers
Our codebase has a shared library that defines enumerated region types and helper methods for mapping between resources.
If a service needs to resolve a region-specific database ID or S3 path, it can consistently do so programmatically based on its current region, rather than through hard-coded logic.
Centralized resources
For resources that don't contain customer data—such as configuration files or shared job definitions—we keep them centralized instead of duplicating them per region. Examples include storing data in a shared S3 bucket or maintaining a single Airflow orchestration layer as described earlier. This reduces operational overhead and helps maintain consistency across environments.
Maintainability for data users
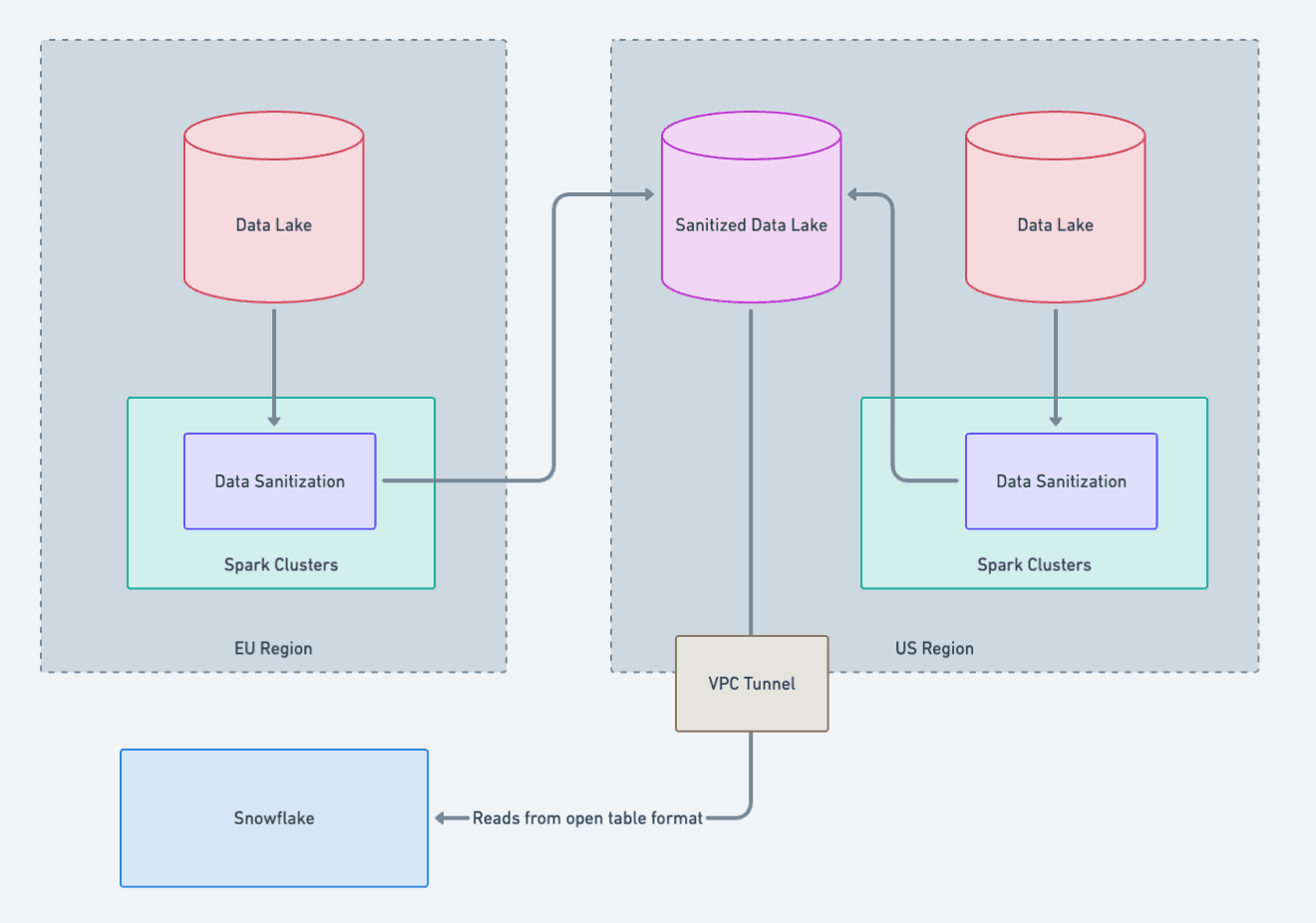
Centralized Analytics and Data Sanitization
The data engineering and data science teams at Notion rely on a wide range of models, queries, notebooks, and dashboards developed over time in our centralized Snowflake data warehouse. They're primarily used for product analytics and operational insights that don't rely on sensitive user data, such as workspace seat counts or revenue metrics.
Some of the data in the warehouse is sourced from our data lake, but only after a careful sanitization process to first remove any customer data.
To make data residency work for these teams, we continue to rely on a single centralized Snowflake environment, because rewriting everything to be region-aware would be impractical and disruptive. To achieve this, we run a data sanitization pipeline that removes all customer data before anything leaves its region.
In the EU, data is first processed in the EU data lake, where a Spark job sanitizes it locally before it lands into our centralized Snowflake environment. The US follows the same process with its own sanitization pipeline.
For our internal users, this means there’s just one unified dataset to query. Region information is present, so teams can filter by region when needed, but their existing queries and models continue to work without major changes.
Next steps
Europe was just the beginning! Notion is a growing business, with customers all over the world. Everything we’ve described above took months to complete, and one of our biggest challenges will be how to make it easier and faster to expand into new regions. Our ultimate goal is that we should be able to roll out the data stack to a new within days, not months. With that being said, we’re already reapplying our learnings from setting up Europe and will soon expand to provide data residency in Japan and South Korea.
Making data residency work at Notion required collaboration across multiple teams, shared abstractions, and intentional design choices that make multi-region infrastructure maintainable, scalable, and safe.
By designing our systems so that data is processed and stored within its region—and by centralizing the right pieces to keep it manageable—we've built a foundation that helps Notion scale globally while continuing to protect customer data and privacy.
