Two years of vector search at Notion: 10x scale, 1/10th cost

Por Preeti Gondi, Mickey Liu, Nathan Louie, Calder Lund, Jacob Sager
When we launched Notion AI Q&A in November 2023, we knew we were embarking on an ambitious journey. What we didn't fully anticipate was just how quickly we'd need to scale, or how dramatically we could optimize our costs once we hit our stride. This is the story of how we scaled our vector search infrastructure by 10x while simultaneously reducing costs by 90 percent over the past two years.
What is vector search and why does Notion AI use it?
Traditional keyword search matches exact words, so a query like “team meeting notes” can miss content titled “group standup summary”, even though they mean the same thing.
Vector search fixes this by turning text into semantic embeddings: points in a high-dimensional space where similar ideas cluster together. This lets us retrieve relevant content based on meaning instead of being limited to exact phrasing.
This is essential for Notion AI, which answers natural-language questions by searching content from across a user’s workspace and connected tools like Slack and Google Drive.
Part 1: Scaling to millions of workspaces
When we launched in November 2023, our ingestion indexing pipeline had two paths:
Offline path: Batch jobs running on Apache Spark that chunk existing documents, generate embeddings via API, and bulk-load vectors into our vector database
Online path: Real-time updates via Kafka consumers that process individual page edits as they happen
This dual-path architecture let us onboard large workspaces efficiently while keeping live workspaces up-to-date with sub-minute latency.
Our vector database ran on dedicated “pod” clusters that coupled storage and compute, and was able to handle large-scale multi-tenant workloads. We designed a sharding strategy similar to our Postgres setup, utilizing workspace ID as a partitioning key and routing to the correct index using range based partitioning. A single config held references to all the shards.
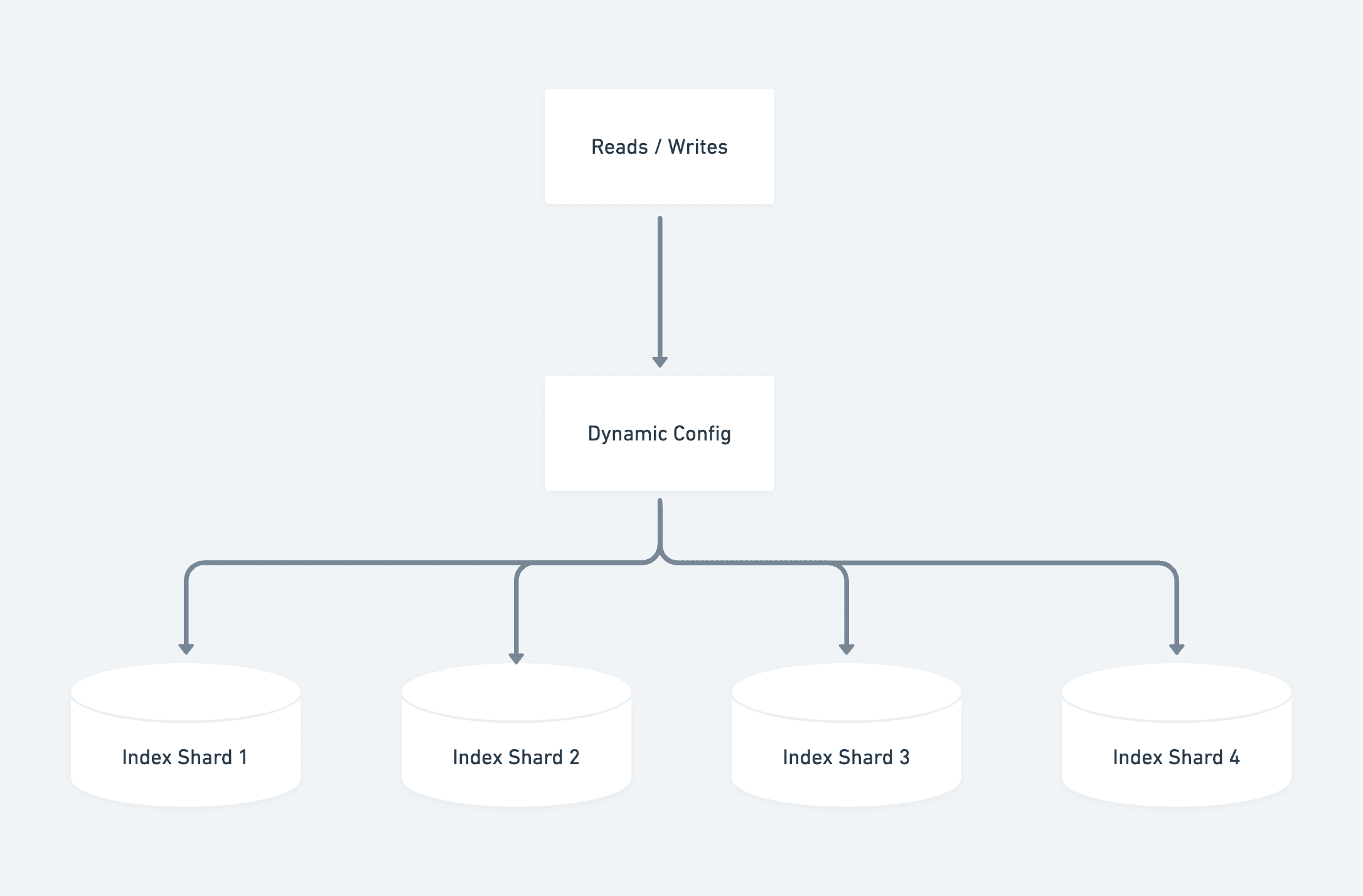
The launch generated immediate and overwhelming demand. We quickly accumulated a waitlist of millions of workspaces eager to access Q&A, and we needed to onboard them as quickly as possible while maintaining quality and performance.
Running low on space
Just one month after launch, our original indexes were close to capacity. If we ran out of space, we’d be forced to pause onboarding—slowing the rollout of our AI features and delaying value for new users. We faced a classic scaling dilemma:
Re-shard incrementally: Clone the data into another index, delete half, and repeat every two weeks as we onboarded new customers
Re-shard to final expected volume: Our chosen vector database provider charged for database uptime, making over-provisioning prohibitively expensive
We chose a different path from our historical Postgres sharding setup. Instead, when a set of indexes approached capacity, we'd provision a new set and direct all new workspace onboarding there. Each set got a "generation" ID that determined where reads and writes would go. This kept us moving without stopping to do any re-shard operations.
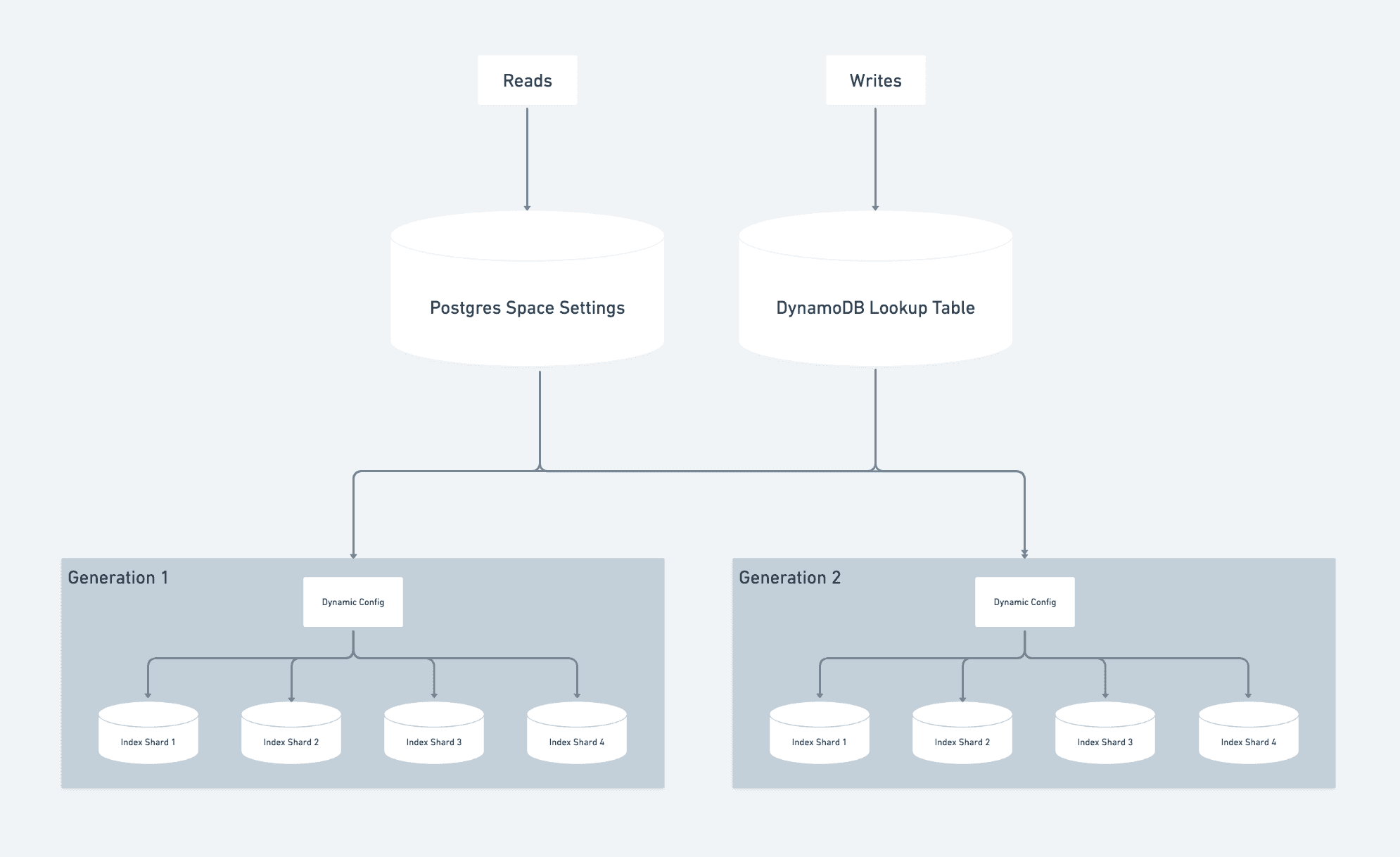
Scaling up
At launch, we could only onboard a few hundred workspaces per day. At that rate, clearing our multi-million waitlist would take decades. With Airflow scheduling, pipelining to maximize throughput, and Spark job tuning, we accelerated our onboarding pace:
Daily onboarding capacity: 600x increase
Active workspaces: 15x growth
Vector database capacity: 8x expansion
By April 2024, we cleared the Q&A waitlist! However, while managing multiple generations of databases got us through the hyper growth stage, it had become operationally complex and expensive. We needed a better architecture.
Part 2: The cost reduction
In May 2024, we migrated our entire embeddings workload from the pre-existing dedicated-hardware “pod” architecture to a new serverless architecture that decoupled storage from compute and charged based on usage rather than uptime.
The benefits were immediate and substantial: A 50 percent cost reduction from peak usage, resulting in several millions of dollars saved annually. The added benefits of the serverless design included the removal of storage capacity constraints that had been a major scaling bottleneck and simplified operations by eliminating the need to provision capacity ahead of demand.
Despite these impressive savings, our annual run rate was still millions per year for vector database costs alone. We knew there was more optimization potential to unlock.
turbopuffer evaluation and migration (May 2024 - January 2025)
In parallel with our initial vector database savings effort, we conducted a comprehensive evaluation of alternative search engines, with turbopuffer emerging as a compelling option with substantially lower projected costs.
At the time, turbopuffer was a newer entrant in the search space, built from the ground up on top of object storage for performance and cost-efficiency. Their architecture aligned with our needs: supporting both managed and bring-your-own-cloud deployment models as well as making it easy to bulk modify stored vector objects. After a successful evaluation, we committed to migrating our entire multi billion object workload to turbopuffer in late 2024.
Since we were switching providers, we took the opportunity to comprehensively overhaul our overall architecture:
Full re-indexing: We increased our writes throughput in our offline indexing pipeline to rebuild the corpus in turbopuffer
Embeddings model upgrade: We switched to a newer, more performant, embeddings model during the migration
Architecture simplification: turbopuffer treats each namespace as an independent index without worrying about sharding or generation routing
Gradual cutover: We migrated generations one at a time, validating correctness before moving to the next
The result:
60 percent cost reduction on search engine spend
35 percent reduction in AWS EMR compute costs
p50 production query latency improved from 70-100ms to 50-70ms
Page State Project (July 2025)
Our next major optimization addressed a fundamental inefficiency in our indexing pipeline. Notion pages can be very long, so we chunk each page into spans, embed each span, and load them into our vector database with metadata like the authors and permissions.

In our original implementation, whenever a page or its properties was edited, we would re-chunk, re-embed, and re-upload all of the spans in that page - even if only a single character changed. Our challenge was to quickly identify when something changed and what work needed to be redone.
There were two things that we cared about changing:
The actual page text: The embedding needed to be updated
The metadata on the page or the text: The metadata needed to be updated
To detect changes, we kept track of two hashes per span: one on the span text, and the other on all of the metadata fields. We used the 64-bit variant of the xxHash algorithm because it balanced ease of use, speed, and low collisions with the storage footprint.
We picked DynamoDB as our caching solution because it provides fast inserts and lookups. We have one record per page, with a struct of all the spans on the page and their text and metadata hashes.

Case 1: The page text changes
Imagine Herman Melville is working on Moby Dick and makes an edit midway through the page. Previously, we would have re-embedded and loaded the whole page. Now, we chunk the page, get the previous state of the page from DynamoDB, and compare all the text hashes. We detect exactly which spans changed, and only re-embed and re-load those spans into our vector database.

Case 2: the metadata changes
Now, Melville is ready to publish Moby Dick - he modifies the permissions from just him to everyone. We store metadata like permissions on every span, but changing it doesn’t impact the embedding. Previously, we still would have to re-embed and load the whole page. Now, we chunk the page, get the previous state of the page from DynamoDB, and compare all the text and metadata hashes. We detect that all the text hashes are the same, but all the metadata hashes are different. This means we can skip embedding altogether, and just issue a PATCH command to our vector database to update the metadata, a much cheaper operation.

Through both of these changes, we achieved a 70% reduction in data volume which saved money on both embeddings API costs and on vector DB write costs.
Embeddings Indexing on Ray (July 2025 – Present)
In July 2025, we set out to migrating our near real-time embeddings pipeline to Ray running on Anyscale.

Ray is an open-source project that many larger companies build internal teams around (like Spotify). However, we don’t have a dedicated ML infra team here at Notion, and Anyscale (managed Ray from the original Ray team) provides us with the ML platform as a service.
This strategic shift addressed multiple pain points simultaneously:
"Double Compute" problem. Running Spark on EMR for preprocessing (chunking, transformations, orchestrating API calls), then also paying per-token fees to an embeddings API provider
Embeddings Endpoint Reliability. We were dependent on our provider’s API stability to keep our search indexes fresh
Clunky Pipelining. In order to smooth out traffic to our dependent endpoints and avoid API rate limits, we implemented our own pipelining setup that split the online indexing Spark job into multiple jobs that handed off batches of data via S3.
So why Ray and Anyscale?
Model flexibility: Ray lets us run open-source embedding models directly, without being gated by external providers. As new models are released, we can experiment and adopt them immediately
Unified compute: By consolidating preprocessing and inference onto a single compute layer, we eliminated the double-compute problem
GPU/CPU pipelining: Ray natively supports pipelining GPU-bound inference with CPU-bound preprocessing on the same machines, keeping utilization high
Developer productivity: Anyscale's integrated workspaces let our engineers write and test data pipelines from their favorite tools (Cursor, VSCode, etc.) without provisioning infrastructure
Lower query-time latency: Self-hosting embeddings removed a third-party API hop from the critical path, which materially reduced end-to-end latency for user-facing searches.
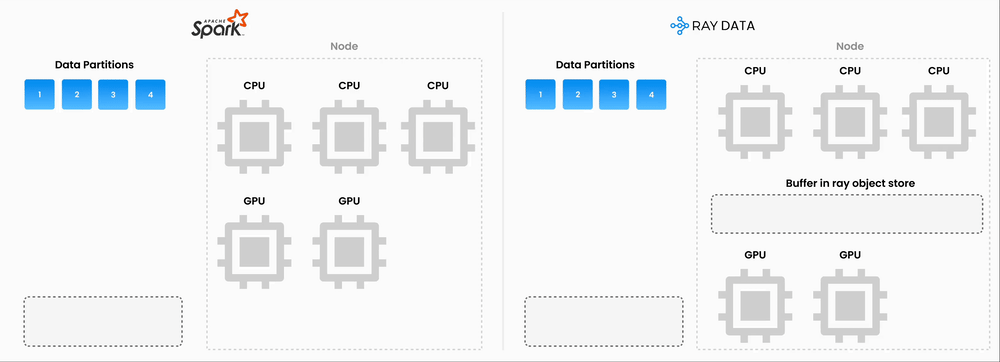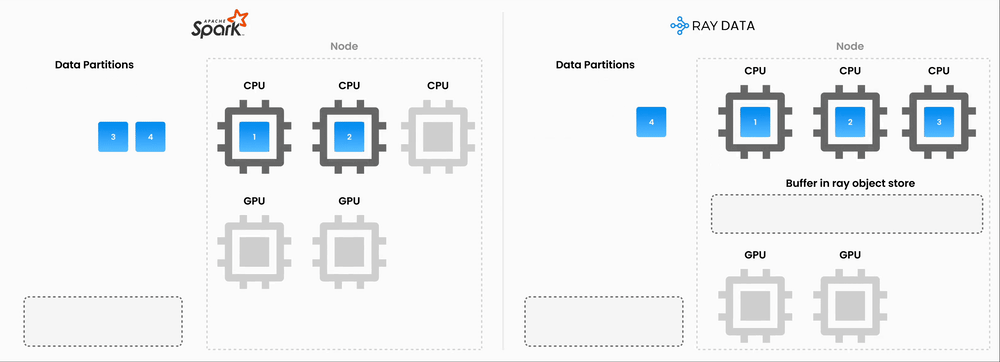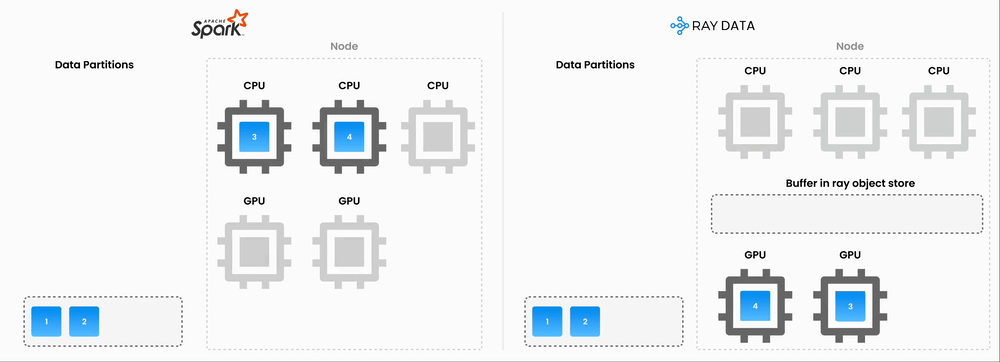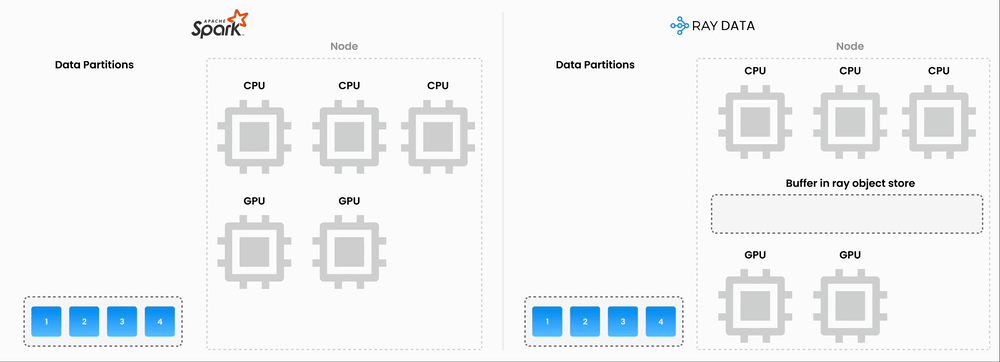
By migrating our embeddings generation pipeline from Spark to Ray, we anticipate a 90+ percent reduction in embeddings infrastructure costs. This is still rolling out, but early results are promising.
Embeddings Serving on Ray (July 2025 – Present)
When users or agents search Notion, we need to embed queries on the fly. We can’t search our vector DB until that computation finishes, so we are very latency sensitive here. However, hosting large-parameter embedding models (like those found on Hugging Face) can be tricky. You need to consider everything from efficient GPU allocation to ingress routing to replication to scaling.
Ray Serve provides most of this out-of-the-box. It allows us to wrap our open-source embedding models in a persistent deployment that stays loaded on the GPU. We can configure everything from dynamic request batching to replication. The model serving code just looks like normal Python, and the compute, replication, and autoscaling configs are plain yaml.
Looking Forward
As we continue to scale, we're excited about future opportunities:
Expanded data sources: We're adding the capability to connect even more tools to give users the most comprehensive answers
Model evolution: We're continuously evaluating new embedding models as the field advances rapidly—Ray gives us the flexibility to adopt them quickly
Pipeline optimization: There's no finish line in infrastructure work. We're always finding new ways to make things faster, cheaper, and more reliable
Notion Agents: Custom Agents (coming soon) leverage AI & vector search across your Notion workspace and connected apps to give your agents the right context, so they can autonomously complete workflows with the same understanding a teammate would have
If you're interested in these kinds of challenges, we're hiring.
