Balancing cost and reliability for Spark on Kubernetes

Por Justin Lee
Software Engineer, Notion
Today, we’re excited to open-source Spot Balancer in collaboration with AWS, a tool that helped us reduce Spark compute costs by up to 90 percent while maintaining reliability.
At Notion, we use Spark for many types of production workloads that process large amounts of data. Some jobs are short, while others run for hours, storing and moving massive datasets between hundreds of workers.
As our workloads grew, it became important to reduce infrastructure costs without sacrificing reliability. We built a cost-efficient Spark setup on Kubernetes, but pushing the savings further led to failures that Spark could not handle well.
To solve this, we created Spot Balancer. This tool lets Spark jobs choose between cost and stability. Along with better resource use from our Kubernetes-based infrastructure, it has helped us save 60-90 percent on costs across our workloads.
Spark processes data with fault-tolerant executors
Spark is designed to process data across many machines. A driver manages the work across executors, which can be added or removed as the job runs. Executors exchange data through shuffle operations. Spark handles single-executor failures well by retrying tasks, recomputing data, and typically keeping the job moving forward.
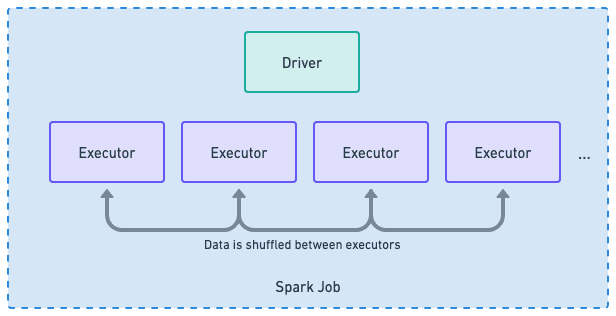
However, Spark can struggle when many executors are lost simultaneously. If this happens, shuffle data is lost, recomputation becomes expensive, and retries can make things worse instead of helping. Jobs that were running smoothly can fail completely.
We eventually encountered this kind of failure during our cost-savings journey.
The warmup: Consolidating Spark execution on Kubernetes
We used to run Spark on Amazon EMR with fixed EC2 instances. As our usage increased, this setup became limiting and created significant maintenance overhead. Clusters were often overprovisioned, underutilized, or required tuning for each job.
We switched to EMR on EKS, keeping EMR’s APIs and tools but running jobs on a shared Kubernetes platform. This gave us centralized infrastructure and enabled cost optimization across all jobs simultaneously.
Step 1: Cost efficiency through dynamic provisioning and efficient bin packing
On Kubernetes, we use Karpenter with EKS Auto Mode for node management.
Using this setup, Spark jobs do not need to set instance types or cluster sizes. They state their CPU and memory requirements, and Karpenter picks the optimal capacity, starts nodes as needed, and removes them when they are no longer needed. This dynamic provisioning both simplified and optimized our node management.
We added the MostAllocated scheduler to efficiently place executors from different jobs on the same nodes, prioritizing existing capacity. This concept, known as bin-packing, helps us use existing nodes before adding new ones. This way, we can run more work on the same hardware and minimize costs for underutilized nodes.
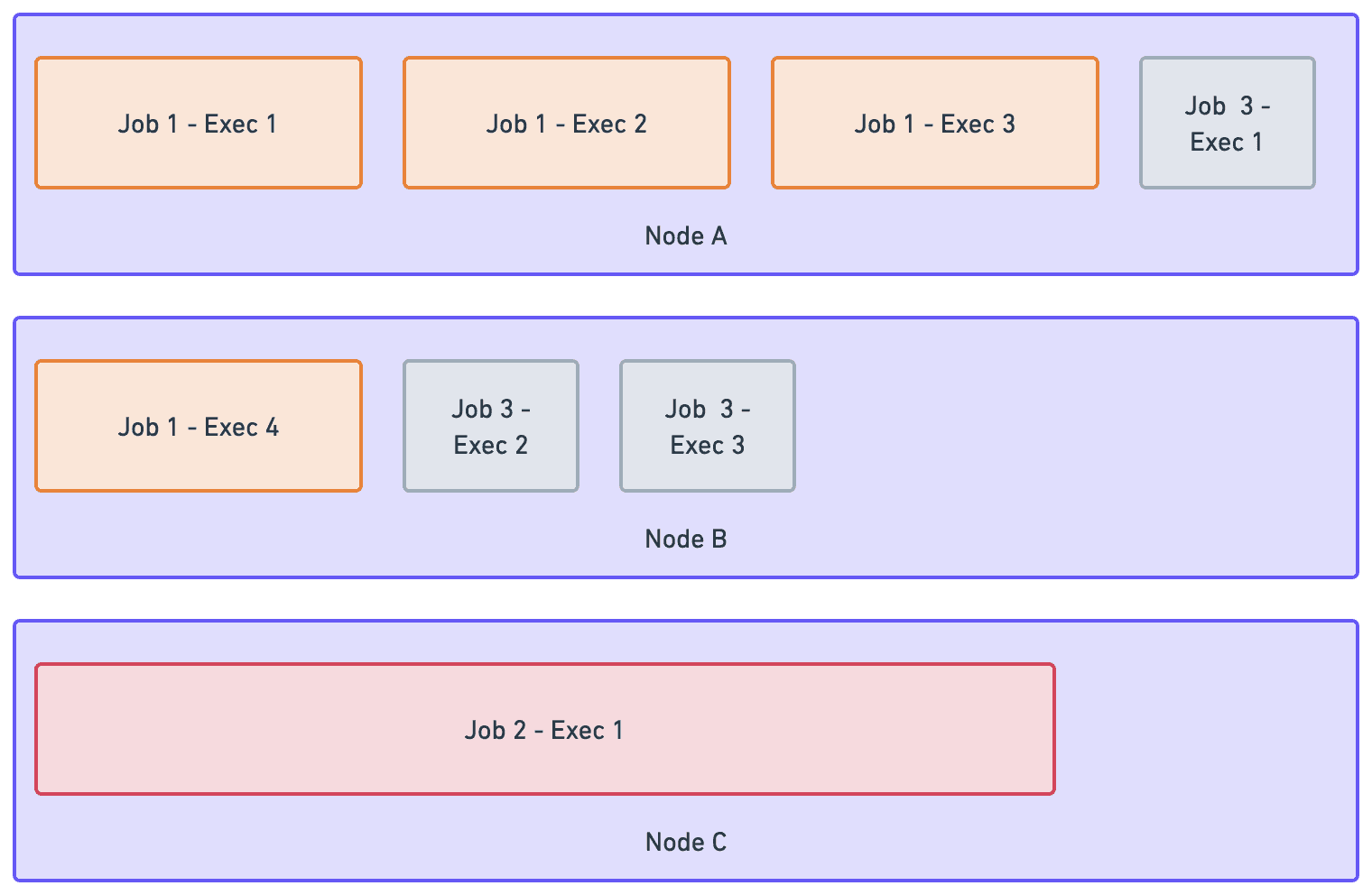
The diagram above shows a simplified example of how node allocation and bin-packing work, assuming all hardware has uniform capacity. In the diagram, executor width represents the resources an executor requires, while node width represents a node's total capacity.
Job 1requests executors, and Karpenter provisionsNode AandNode Bbecause the executors do not fit on a single node.Job 2requests executors, and Karpenter provisionsNode C.Job 3requests executors, Kubernetes detects capacity, and bin-packs onto existing nodes, without needing Karpenter to run.
With these changes, we removed most obvious inefficiencies, such as idle nodes, over-provisioned clusters, and poor bin packing. Still, we saw more room for improvement.
Step 2: Cost efficiency with Spot Instances—too good to be true?
AWS offers a type of node called Spot Instances, which are discounted by up to 90 percent, but they can be interrupted at any time. When this happens, the instance and its processes are terminated. In theory, this works fine for short Spark jobs, provided they finish processing before the node is interrupted.
In practice, our jobs using Spot Instances often failed. The effect was likely due to many executors being bin-packed onto a larger Spot Instance. If a spot interruption occurs, the job may fail if too many executors terminate at once, or it may slow down significantly as it recovers lost data.
Since Karpenter operates at the cluster level, jobs’ executors can be disproportionately placed on Spot Instances. Without precise node placement controls, a single spot interruption can simultaneously eliminate many of a job’s executors.
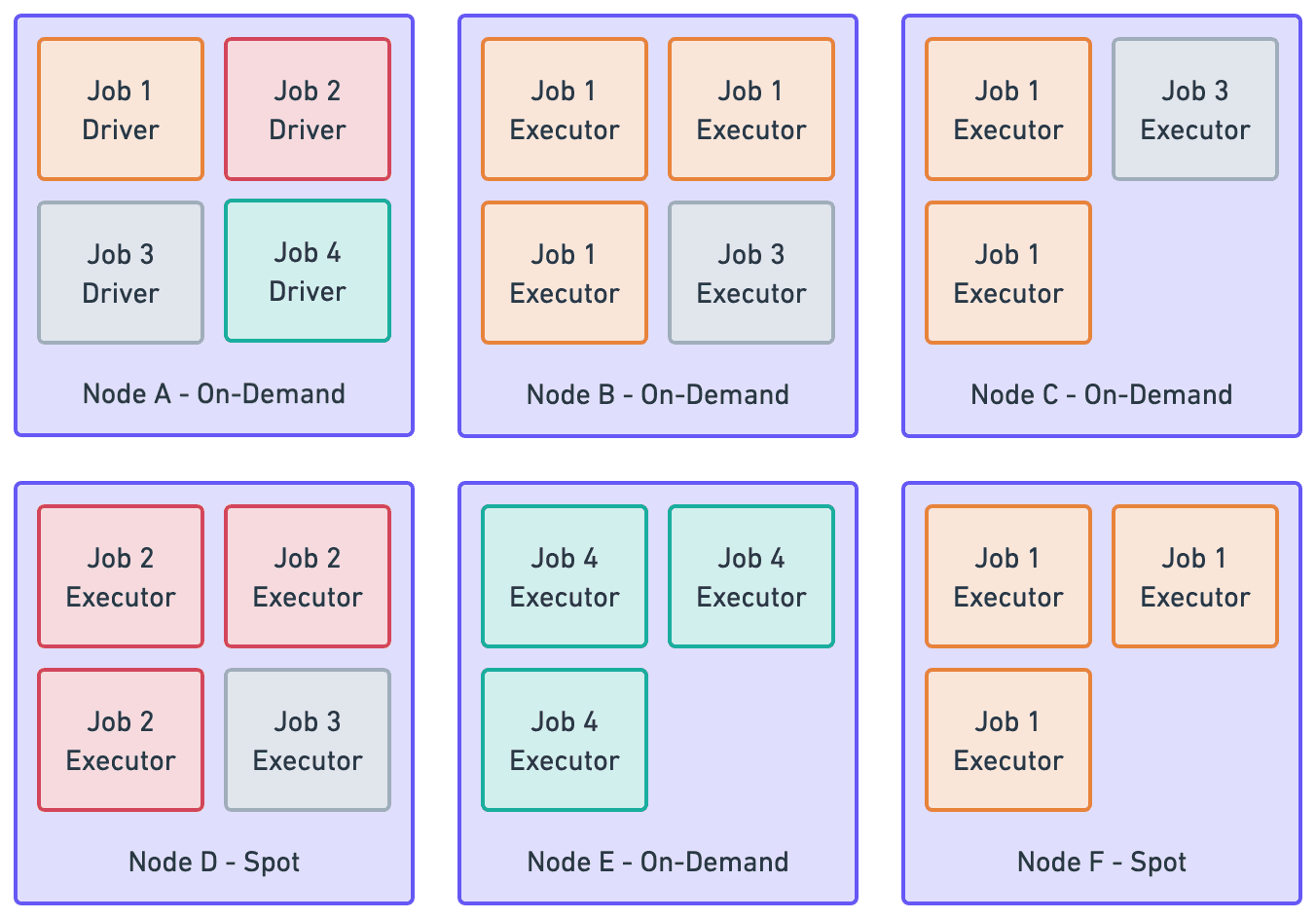
The diagram above illustrates the impact of executor placement:
Without Spot Instance:
Node Ewould not be interrupted since it runs with on-demand capacity.Job 4is stable, but it does not benefit from spot cost savings.With Spot Instance: If
Node Dis interrupted,Job 2is likely to fail because all of its executors run on spot capacity.With Distributed Spot and On-Demand Instances: If
Node Fis interrupted,Job 1is likely to continue running because its executors are split across spot and on-demand nodes.
Attempting to tune graceful failures
AWS provides a two-minute warning before ending a Spot Instance, and we thought adjusting our setup for this notice might solve the problem.
Karpenter can see the termination notice, drain nodes, and add new capacity. This works for stateless services like REST APIs that restart quickly, but it did not work well for Spark.
Spark has a decommissioning feature that copies data to another node. But with our large Spark jobs, it often could not finish moving the data before the instance was terminated.
This showed us the real problem wasn't a matter of configuration. We needed a way to control how much a Spark job uses Spot Instances, while still using Spark’s built-in retries and recovery. This idea led us to create Spot Balancer.
The solution: We built the Spot Balancer
Spot Balancer is a Kubernetes tool that manages how a Spark job’s executors are split between spot and on-demand capacity. This gives us more control over spot usage per job, not just across the whole cluster.
Each Spark job sets its own target, such as 70 percent spot and 30 percent on-demand. Spot Balancer maintains the desired ratio, so even if spot interruptions occur, only a small, expected number of executors are lost. Jobs that run longer or need more stability use more on-demand, while short or less essential jobs can use more spot.
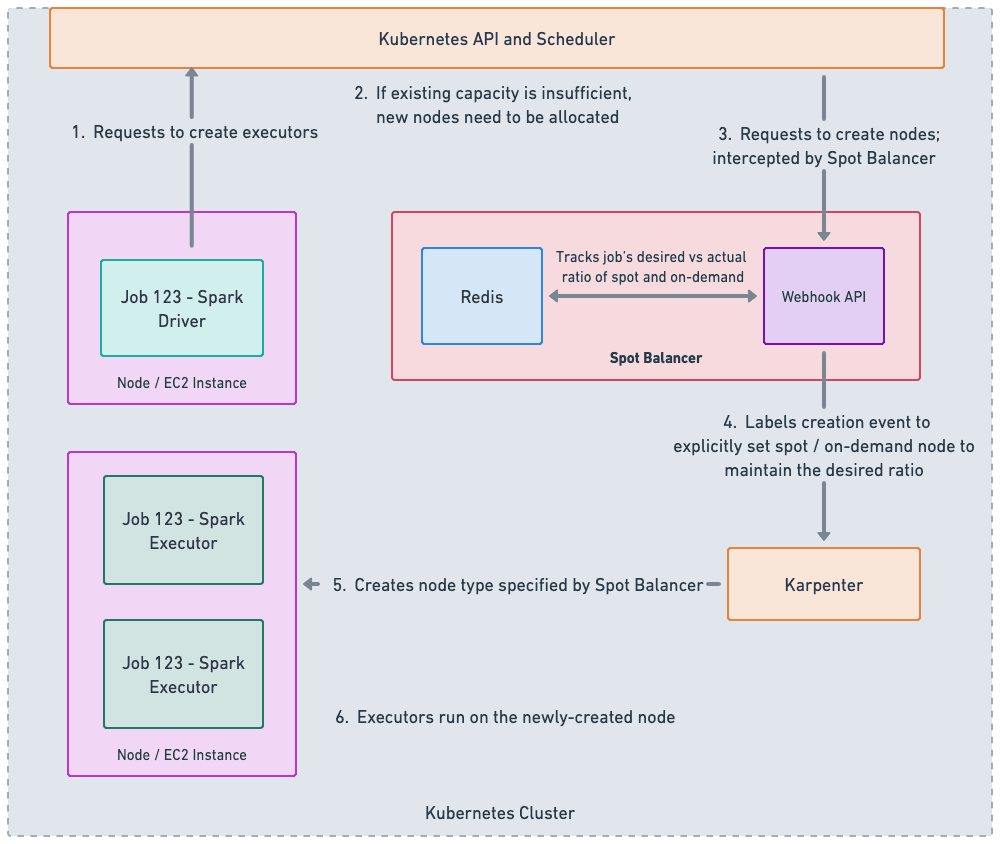
Spot Balancer tracks each job's executor count across spot and on-demand instances and stores this in Redis. It works as a Kubernetes webhook, intercepting executor creation and labeling each one based on the job’s spot ratio, so Karpenter is explicitly told to use spot or on-demand capacity.
After we started using Spot Balancer, jobs that used to fail from spot interruptions began to finish reliably. This gave us the confidence to use spot instances more widely in our systems.
Applying craft to our tooling
Internally, Spot Balancer uses a scale from 0.0 to 1.0 to specify the desired ratio between spot and on-demand capacity. Raw numbers, however, are not a great interface.
While raw ratios are flexible, we want our Spark users to focus on creating and maintaining Spark jobs, not on weighing infrastructure trade-offs within the platform. We offer a few named stability weights with self-documenting guidance.

In this case, choosing RELIABILITY_OVER_COST clearly means the job will require more on-demand capacity and cost more. This makes the trade-off clear, so engineers can choose intentionally rather than always picking the safest option without considering cost.
While simple, this interface enabled engineers to self-manage their spot ratios.
We open sourced it!
We built Spot Balancer at Notion to solve a real production problem that existing tools couldn't address. The class of failures it solves is common for teams running Spark on Kubernetes with spot capacity.
Now, we are open-sourcing Spot Balancer in collaboration with AWS and making it available for others to use on their own Spark platforms.
Closing
By consolidating our infrastructure, we can apply cost optimizations across the board and make the tools engineers use every day simpler.
We used Karpenter’s cost-effective node provisioning and the MostAllocated scheduler to boost efficiency, then built Spot Balancer to use Spot Instances reliably. This helped us cut Spark compute costs by 60-90 percent across our workloads without sacrificing reliability.
If this work interests you, check out our careers page!
