بناء وتوسيع بحيرة بيانات Notion

بواسطة XZ Tie, Nathan Louie, Thomas Chow, Darin Im, Abhishek Modi, Wendy Jiao
في السنوات الثلاث الماضية، توسعت بيانات Notion بمقدار 10 أضعاف بسبب نمو المستخدمين والمحتوى، بمعدل تضاعف يتراوح بين 6-12 شهراً. إدارة هذا النمو السريع مع تلبية الطلبات المتزايدة باستمرار على البيانات من حالات الاستخدام الحرجة للمنتجات والتحليلات، خاصة ميزات Notion AI الأخيرة، تعني بناء وتوسيع بحيرة بيانات Notion. إليك كيف فعلنا ذلك.
نموذج بيانات Notion ونموها
كل ما تراه في Notion - نصوص، صور، عناوين، قوائم، صفوف قاعدة بيانات، صفحات، إلخ - على الرغم من اختلاف تمثيلاته وسلوكياته في الواجهة الأمامية، يتم نمذجته ككيان "كتلة" في الخلفية ويتم تخزينه في قاعدة بيانات Postgres بهيكل متسق، ومخطط، وبيانات وصفية مرتبطة (تعرف على المزيد حول نموذج بيانات Notion).
لقد تضاعف كل هذا البيانات الكتلية كل 6 إلى 12 شهراً، مدفوعاً بنشاط المستخدمين وإنشاء المحتوى. في بداية عام 2021، كان لدينا أكثر من 20 مليار صف كتلة في Postgres، ومنذ ذلك الحين زاد هذا الرقم إلى أكثر من مئتي مليار كتلة - حجم بيانات يصل إلى مئات التيرابايت، حتى عند الضغط.
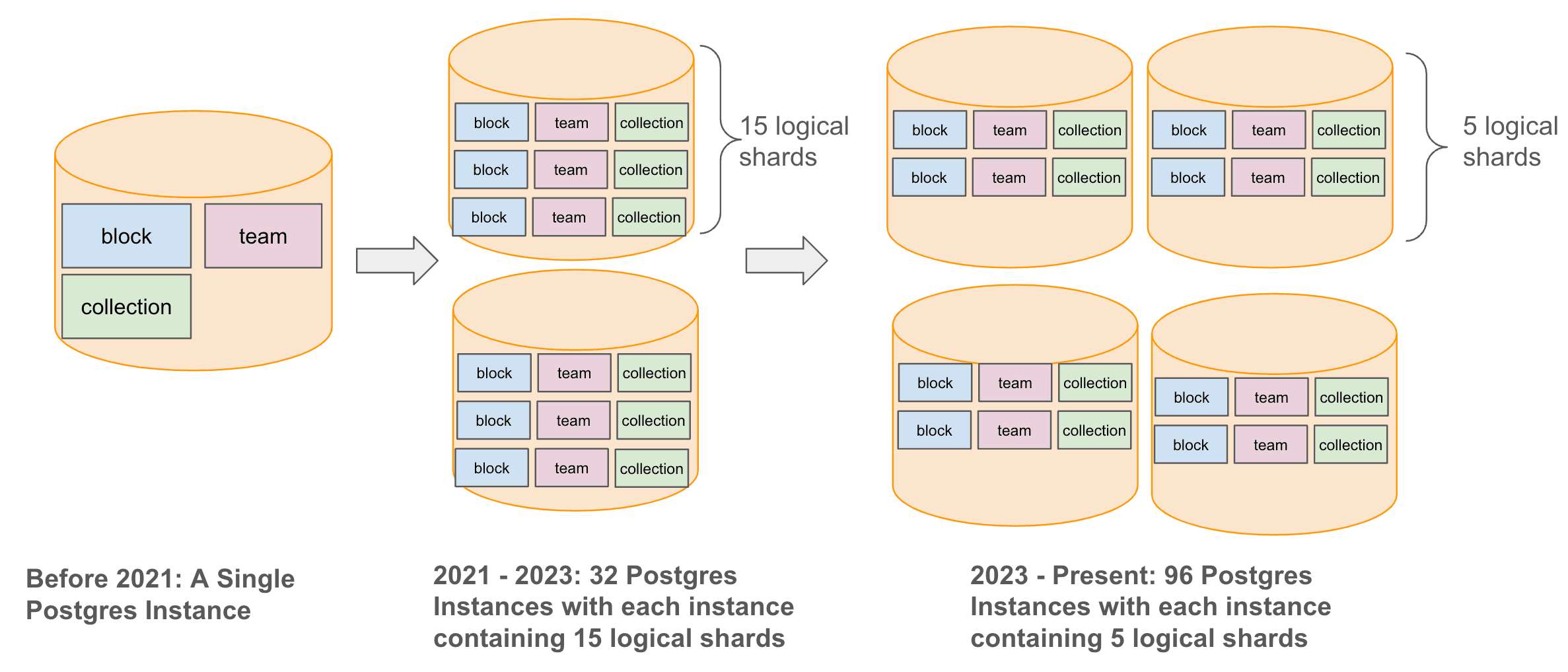
لإدارة هذا النمو في البيانات مع تحسين تجربة المستخدم، قمنا بتوسيع بنية قاعدة البيانات لدينا بشكل استراتيجي من مثيل واحد من Postgres إلى بنية معقدة أكثر مقسمة. بدأنا في عام 2021 عن طريق تقسيم قاعدة بيانات Postgres الخاصة بنا أفقياً إلى 32 مثيلاً مادياً، كل منها يتكون من 15 شريحة منطقية، واستمرينا في عام 2023 عن طريق زيادة عدد المثيلات المادية إلى 96، مع خمس شرائح منطقية لكل مثيل. وبذلك حافظنا على إجمالي 480 شريحة منطقية مع ضمان قدرات إدارة واسترجاع بيانات قابلة للتوسع على المدى الطويل.
بحلول عام 2021، كانت Postgres تشكل جوهر بنية الإنتاج لدينا، حيث تتعامل مع كل شيء من حركة مرور المستخدمين عبر الإنترنت إلى احتياجات التحليلات والذكاء الاصطناعي المختلفة. مع زيادة الطلبات على البيانات عبر الإنترنت وغير المتصلة، أدركنا أنه من الضروري بناء بنية بيانات مخصصة للتعامل مع البيانات غير المتصلة دون التأثير على حركة المرور عبر الإنترنت.
بنية مستودع بيانات Notion في عام 2021
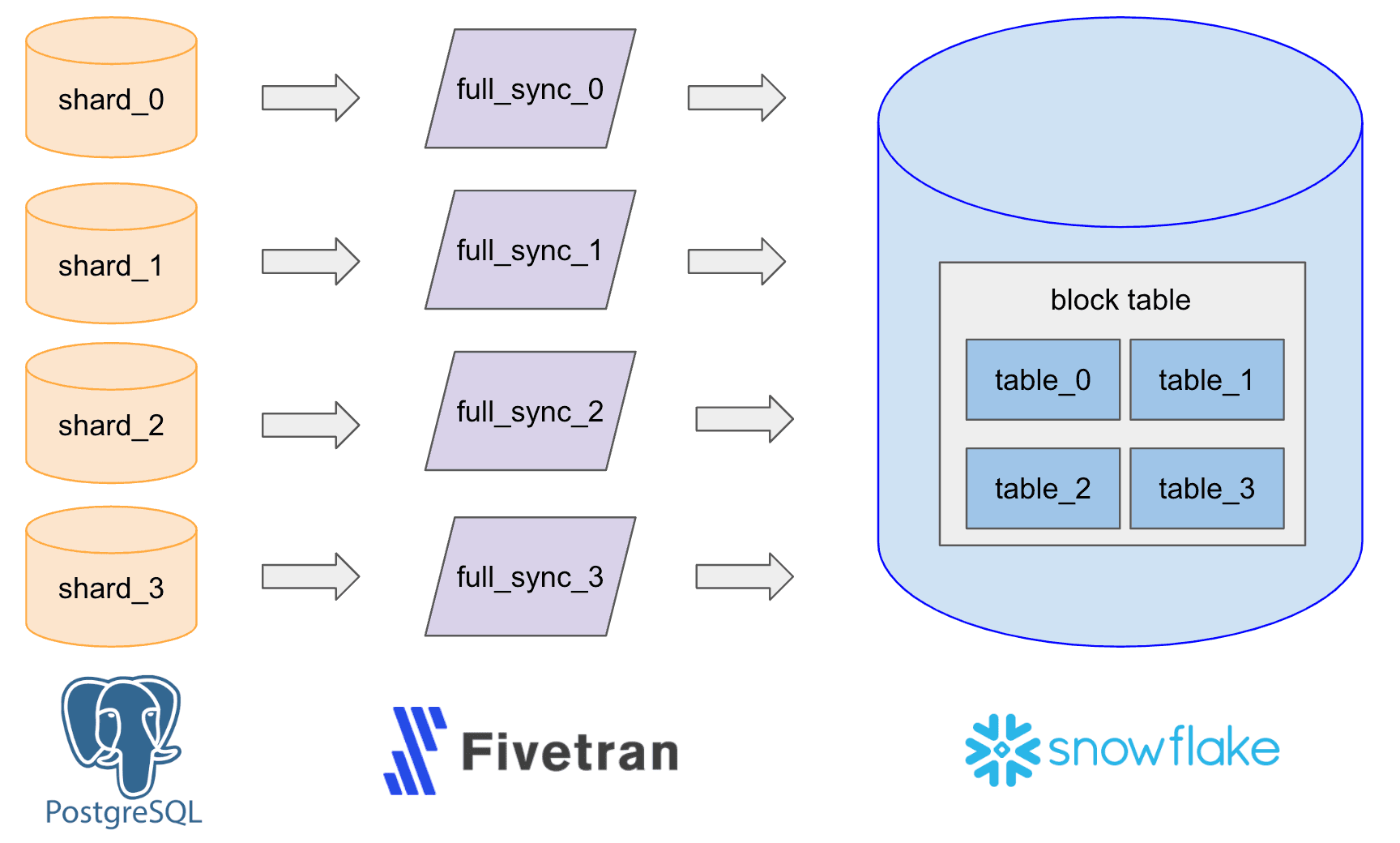
في عام 2021، بدأنا هذه البنية التحتية المخصصة للبيانات مع خط أنابيب ELT (استخراج، تحميل، وتحويل) بسيط استخدم الأداة الخارجية Fivetran لاستيراد البيانات من سجل الكتابة المتقدم Postgres (WAL) إلى Snowflake وإعداد 480 موصلاً يعمل كل ساعة لـ 480 شريحة لكتابة نفس العدد من جداول Snowflake الخام. ثم قمنا بدمج هذه الجداول في جدول كبير واحد لأغراض التحليلات، والتقارير، وحالات استخدام التعلم الآلي.
تحديات التوسع
مع نمو بيانات Postgres لدينا، واجهنا العديد من تحديات التوسع.
قابلية التشغيل
أصبح عبء مراقبة وإدارة 480 موصل Fivetran، بالإضافة إلى إعادة مزامنتها خلال إعادة تقسيم Postgres، والترقيات، وفترات الصيانة، مرتفعاً للغاية، مما خلق عبئاً كبيراً على أعضاء الفريق.
السرعة، حداثة البيانات والتكلفة
أصبح إدخال البيانات إلى Snowflake أبطأ وأكثر تكلفة، ويرجع ذلك أساساً إلى عبء العمل الفريد الذي يعتمد على التحديثات في Notion. يقوم مستخدمو Notion بتحديث الكتل الموجودة (النصوص، العناوين، العناوين الرئيسية، قوائم النقاط، صفوف قاعدة البيانات، إلخ) بشكل متكرر أكثر من إضافتهم لكُتل جديدة. هذا يجعل بيانات الكتل تعتمد بشكل كبير على التحديثات - 90% من عمليات الإدخال والتحديث في Notion هي تحديثات. تم تحسين معظم مستودعات البيانات، بما في ذلك Snowflake، لأعباء العمل التي تعتمد على الإدخال، مما يجعل من الصعب بشكل متزايد عليها إدخال بيانات الكتل.
دعم حالات الاستخدام
أصبحت منطق تحويل البيانات أكثر تعقيداً وثقلاً، متجاوزة قدرات واجهة SQL القياسية التي تقدمها مستودعات البيانات الجاهزة.
إحدى حالات الاستخدام المهمة هي بناء وجهات غير طبيعية لبيانات كتل Notion للمنتجات الرئيسية (مثل الذكاء الاصطناعي والبحث). تضمن بيانات الأذونات، على سبيل المثال، أن الأشخاص المناسبين فقط يمكنهم قراءة أو تغيير كتلة (هذه المدونة تناقش نموذج أذونات كتل Notion). لكن إذن الكتلة لا يتم تخزينه بشكل ثابت في Postgres المرتبط - يجب بناؤه في الوقت الفعلي عبر حسابات شجرة مكلفة.
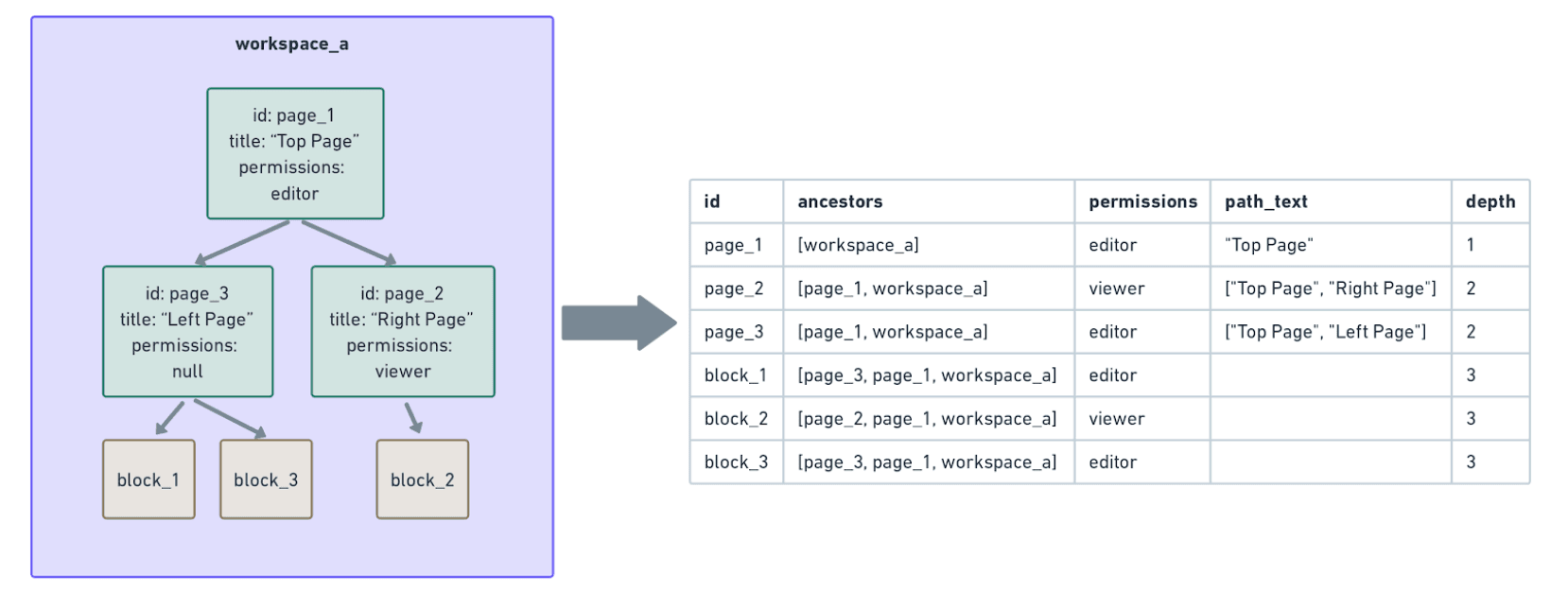
في المثال التالي،
block_1،block_2، وblock_3ترث الأذونات من والديها المباشرين (page_3وpage_2) وأسلافها (page_1وworkspace_a).لبناء بيانات الأذونات لكل من هذه الكتل، يجب علينا التنقل في شجرة أسلافها حتى الجذر (workspace_a) لضمان الاكتمال. مع وجود مئات المليارات من الكتل التي تتراوح أعماق أسلافها من بضع إلى عشرات، كانت هذه النوعية من الحسابات مكلفة للغاية وكانت ستنتهي ببساطة في Snowflake.
بسبب هذه التحديات، بدأنا في استكشاف بناء بحيرة البيانات الخاصة بنا.
بناء وتوسيع بحيرة البيانات الداخلية لـ Notion
كانت أهدافنا لبناء بحيرة بيانات داخلية كالتالي:
إنشاء مستودع بيانات قادر على تخزين كل من البيانات الخام والمعالجة على نطاق واسع.
تمكين إدخال البيانات وحسابها بسرعة وقابلية التوسع والتشغيل وكفاءة التكلفة لأي عبء عمل - خاصة بيانات الكتل التي تتطلب تحديثات كثيرة في Notion.
فتح الذكاء الاصطناعي والبحث وحالات استخدام المنتج الأخرى التي تتطلب بيانات غير طبيعية.
ومع ذلك، بينما يعد بحيرة البيانات لدينا خطوة كبيرة إلى الأمام، من المهم توضيح ما لا يُقصد به القيام به:
استبدال Snowflake بالكامل. سنستمر في الاستفادة من سهولة التشغيل والنظام البيئي لـ Snowflake من خلال استخدامه لمعظم أعباء العمل الأخرى، وخاصة تلك التي تتطلب إدخالات كثيرة ولا تحتاج إلى تنقل شجرة غير طبيعية على نطاق واسع.
استبدال Fivetran بالكامل. سنستمر في الاستفادة من فعالية Fivetran مع الجداول التي لا تتطلب تحديثات كثيرة، وإدخال مجموعات بيانات صغيرة، ومصادر ووجهات بيانات متنوعة من طرف ثالث.
دعم حالات الاستخدام عبر الإنترنت التي تتطلب زمن وصول من الدرجة الثانية أو أكثر صرامة. ستركز بحيرة بيانات Notion بشكل أساسي على أعباء العمل غير المتصلة التي يمكن أن تتحمل دقائق إلى ساعات من زمن الوصول.
تصميم بحيرة البيانات لدينا على مستوى عالٍ
منذ عام 2022، استخدمنا بنية بحيرة البيانات الداخلية الموضحة أدناه. نقوم بإدخال بيانات محدثة بشكل تدريجي من Postgres إلى Kafka باستخدام موصلات Debezium CDC، ثم نستخدم Apache Hudi، وهو إطار عمل مفتوح المصدر لمعالجة البيانات وتخزينها، لكتابة هذه التحديثات من Kafka إلى S3. مع هذه البيانات الخام، يمكننا بعد ذلك إجراء التحويل، والتنظيم غير الطبيعي (مثل: تنقل الشجرة وبناء بيانات الأذونات لكل كتلة)، والإثراء، ثم تخزين البيانات المعالجة في S3 مرة أخرى أو في الأنظمة السفلية لتلبية احتياجات التحليلات والتقارير، بالإضافة إلى الذكاء الاصطناعي والبحث ومتطلبات المنتجات الأخرى.
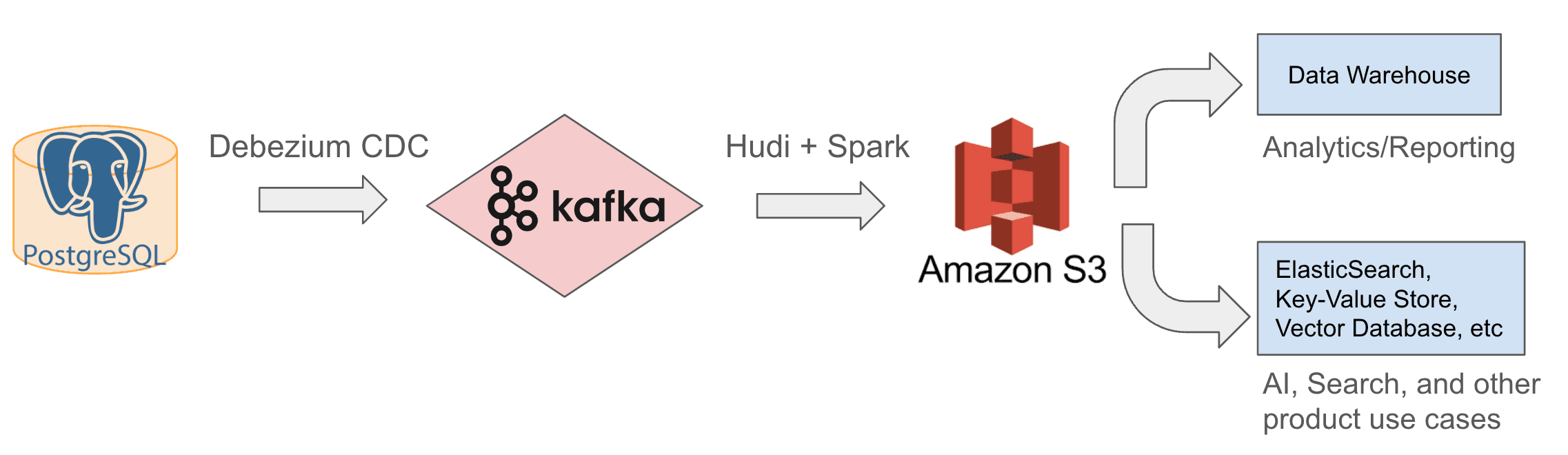
بعد ذلك، سنصف ونوضح مبادئ التصميم والقرارات التي توصلنا إليها بعد بحث ومناقشة وتجريب مكثف.
قرار التصميم 1: اختيار مستودع بيانات وبحيرة
كان قرارنا الأول هو استخدام S3 كمستودع بيانات وبحيرة لتخزين جميع البيانات الخام والمعالجة، وتحديد مستودعات البيانات الأخرى التي تواجه المنتج مثل ElasticSearch، وقاعدة بيانات المتجهات، ومخزن القيم الرئيسية، وما إلى ذلك كأنظمة سفلية لها. اتخذنا هذا القرار لسببين:
لقد توافق مع مجموعة تقنيات AWS الخاصة بـ Notion، على سبيل المثال، قاعدة بيانات Postgres الخاصة بنا تعتمد على AWS RDS وميزة التصدير إلى S3 (الموصوفة في الأقسام اللاحقة) تتيح لنا بسهولة بدء جداول في S3.
لقد أثبت S3 قدرته على تخزين كميات كبيرة من البيانات ودعم محركات معالجة البيانات المختلفة (مثل Spark) بتكلفة منخفضة.
من خلال تحميل أعباء الإدخال والحساب الثقيلة إلى S3 وإدخال بيانات نظيفة للغاية وحرجة للأعمال فقط إلى Snowflake ومستودعات البيانات التي تواجه المنتج، قمنا بتحسين قابلية التوسع وسرعة حساب البيانات بشكل كبير وتقليل التكلفة.
قرار التصميم 2: اختيار محرك المعالجة الخاص بنا
اخترنا Spark كأهم محرك لمعالجة البيانات لأنه كإطار عمل مفتوح المصدر، يمكن إعداده وتقييمه بسرعة للتحقق من أنه يلبي احتياجات تحويل البيانات لدينا. يمتلك Spark أربعة فوائد رئيسية:
تتيح مجموعة Spark الواسعة من الوظائف المدمجة وUDFs (وظائف معرفة من قبل المستخدم) بخلاف SQL منطق معالجة بيانات معقد مثل التنقل في الشجرة وإلغاء تطبيع بيانات الكتل، كما هو موضح أعلاه.
يوفر إطار عمل PySpark سهل الاستخدام لمعظم حالات الاستخدام الأخف، وScala Spark المتقدمة لمعالجة البيانات الثقيلة عالية الأداء.
يعالج بيانات كبيرة الحجم (مثل مليارات الكتل ومئات التيرابايت) بطريقة موزعة، ويعرض تكوينات واسعة، مما يسمح لنا بضبط التحكم في تقسيم البيانات، وانحراف البيانات، وتخصيص الموارد. كما يمكّننا من تقسيم الوظائف المعقدة إلى مهام أصغر وتحسين تخصيص الموارد لكل مهمة، مما يساعدنا على تحقيق وقت تشغيل معقول دون توفير زائد أو إهدار الموارد.
أخيراً، يوفر الطابع المفتوح المصدر لـ Spark فوائد من حيث الكفاءة من حيث التكلفة.
قرار التصميم 3: تفضيل الإدخال التدريجي على تفريغ اللقطة
بعد الانتهاء من تخزين بحيرة البيانات ومحرك المعالجة الخاص بنا، استكشفنا حلولاً لإدخال بيانات Postgres إلى S3. انتهى بنا الأمر إلى النظر في نهجين: الإدخال التدريجي للبيانات المتغيرة ولقطات كاملة دورية لجدول Postgres. في النهاية، استناداً إلى مقارنات الأداء والتكلفة، اخترنا تصميماً هجيناً:
خلال العمليات العادية، إدخال البيانات المتغيرة تدريجياً وتطبيق بيانات Postgres المتغيرة باستمرار على S3.
في حالات نادرة، أخذ لقطة كاملة من Postgres مرة واحدة لتهيئة الجداول في S3.
يضمن النهج التدريجي بيانات أكثر حداثة بتكلفة أقل وبحد أدنى من التأخير (بضع دقائق إلى بضع ساعات، اعتماداً على حجم الجدول). أخذ لقطة كاملة وتفريغها إلى S3، بالمقابل، يستغرق أكثر من 10 ساعات ويكلف ضعف المبلغ، لذا نقوم بذلك بشكل غير متكرر، عند تهيئة جداول جديدة في S3.
قرار التصميم 4: تبسيط الإدخال التدريجي
موصل Kafka CDC لـ Postgres → إلى → Kafka
اخترنا موصل Kafka Debezium CDC (التقاط البيانات المتغيرة) لنشر بيانات Postgres المتغيرة تدريجياً إلى Kafka، مشابهاً لطريقة إدخال البيانات الخاصة بـ Fivetran. اخترناها مع Kafka بسبب قابليتها للتوسع، وسهولة الإعداد، والتكامل الوثيق مع بنيتنا التحتية الحالية.
هودي لكافكا → إلى → S3
لإدخال البيانات المتزايدة من كافكا إلى S3، اعتبرنا ثلاث حلول ممتازة لبحيرات البيانات والإدخال: أباتشي هودي، أباتشي آيسبرغ، وداتا بريكس دلتا ليك. في النهاية اخترنا هودي لأدائه الممتاز مع عبء العمل الثقيل على التحديثات وطبيعته مفتوحة المصدر والتكامل الأصلي مع رسائل ديبيزيوم CDC.
بينما لم تكن آيسبرغ ودلتا ليك، من ناحية أخرى، محسّنة لعبء العمل الثقيل على التحديثات عندما اعتبرناها في عام 2022. كما أن آيسبرغ كانت تفتقر إلى حل جاهز يفهم رسائل ديبيزيوم؛ بينما دلتا ليك لديها واحد، لكنه ليس مفتوح المصدر. كان علينا أن ننفذ مستهلك ديبيزيوم الخاص بنا إذا كنا سنذهب مع أي من تلك الحلول.
قرار التصميم 5: إدخال البيانات الخام قبل المعالجة
أخيراً، قررنا إدخال بيانات بوستجرس الخام إلى S3 دون معالجة فورية من أجل إنشاء مصدر واحد للحقيقة وتبسيط تصحيح الأخطاء عبر كامل خط بيانات. بمجرد أن تكون البيانات الخام في S3، نقوم بعد ذلك بالتحويل، والتفكيك، والإثراء، وأنواع أخرى من معالجة البيانات. نخزن البيانات الوسيطة في S3 مرة أخرى وندخل فقط البيانات المنظفة بشكل كبير، والمهيكلة، والحرجة للأعمال إلى الأنظمة السفلية للتحليلات، والتقارير، واحتياجات المنتجات.
توسيع وتشغيل بحيرة البيانات لدينا
قمنا بتجربة العديد من الإعدادات التفصيلية من أجل مواجهة تحديات قابلية التوسع المرتبطة بحجم بيانات Notion المتزايد باستمرار. إليك ما جربناه وكيف سارت الأمور:
1. موصل CDC وإعداد كافكا
قمنا بإعداد موصل واحد من ديبيزيوم CDC لكل مضيف بوستجرس ونشرها في مجموعة AWS EKS. بسبب نضج ديبيزيوم وإدارة EKS وقابلية توسيع كافكا، لم نضطر سوى لترقية مجموعات EKS وكافكا بضع مرات في العامين الماضيين. اعتباراً من مايو 2024، يتعامل بسلاسة مع عشرات من تغييرات صفوف بوستجرس في الثانية.
كما نقوم بتكوين موضوع كافكا واحد لكل جدول بوستجرس وندع جميع الموصلات التي تستهلك من 480 شظية تكتب إلى نفس الموضوع لذلك الجدول. هذا الإعداد قلل بشكل كبير من تعقيد الحفاظ على 480 موضوعاً لكل جدول وسهل إدخال هودي إلى S3، مما قلل بشكل كبير من الأعباء التشغيلية.
2. إعداد هودي
استخدمنا Apache Hudi Deltastreamer، وهو وظيفة إدخال قائمة على Spark، لاستهلاك رسائل Kafka وتكرار حالة جدول Postgres في S3. بعد عدة جولات من تحسين الأداء، أنشأنا إعداد إدخال سريع وقابل للتوسع لضمان تحديث البيانات. يوفر هذا الإعداد تأخيراً لا يتجاوز بضع دقائق لمعظم الجداول، وما يصل إلى ساعتين لأكبرها، وهو جدول الكتل (انظر الرسم البياني أدناه).
نستخدم نوع جدول Hudi الافتراضي COPY_ON_WRITE مع عملية UPSERT، والتي تناسب عبء العمل الثقيل على التحديثات لدينا.
لإدارة البيانات بشكل أكثر فعالية وتقليل تضخيم الكتابة (أي، عدد الملفات المحدثة لكل عملية إدخال مجمعة)، قمنا بضبط ثلاث تكوينات:
تقسيم/تجزئة البيانات باستخدام نفس مخطط تجزئة Postgres، أي، تكوين
hoodie.datasource.write.partitionpath.field: db_schema_source_partition. يقسم هذا مجموعة بيانات S3 إلى 480 شظية، منshard0001إلىshard0480,مما يجعل من المرجح أن تتطابق دفعة من التحديثات الواردة مع نفس مجموعة الملفات من نفس الشظية.فرز البيانات بناءً على وقت التحديث الأخير (event_lsn)، أي، تكوين
source-ordering-field: event_lsn. هذا يعتمد على ملاحظتنا أن الكتل الأحدث من المرجح أن يتم تحديثها، مما يسمح لنا بتقليص الملفات التي تحتوي فقط على كتل قديمة.تعيين نوع الفهرس ليكون فلتر بلوم، أي،
hoodie.index.type: BLOOMالتكوين، لتحسين عبء العمل بشكل أكبر.

3. إعداد معالجة بيانات Spark
لأغلب وظائف معالجة البيانات لدينا، نستخدم PySpark، الذي يجعل منحنى التعلم المنخفض نسبياً متاحاً للعديد من أعضاء الفريق. بالنسبة للوظائف الأكثر تعقيداً مثل التنقل في الشجرة وإزالة التطبيع، نستفيد من أداء Spark المتفوق في عدة مجالات رئيسية:
نستفيد من كفاءة الأداء في Scala Spark.
ندير البيانات بشكل أكثر فعالية من خلال التعامل مع الشظايا الكبيرة والصغيرة بشكل منفصل (تذكر أننا احتفظنا بنفس مخطط 480 شظية في S3 لتكون متسقة مع Postgres)؛ يتم تحميل جميع بيانات الشظايا الصغيرة في ذاكرة حاوية مهمة Spark لمعالجة سريعة، بينما يتم إدارة الشظايا الكبيرة التي تتجاوز سعة الذاكرة من خلال إعادة ترتيب القرص.
نستخدم المعالجة المتعددة والخطوط المتوازية لتسريع معالجة 480 شظية، مما يسمح لنا بتحسين وقت التشغيل والكفاءة.
4. إعداد التمهيد
إليك كيفية تمهيد الجداول الجديدة:
نقوم أولاً بإعداد موصل Debezium لاستيعاب تغييرات Postgres إلى Kafka.
بدءاً من الطابع الزمني
t، نبدأ وظيفة تصدير إلى S3 المقدمة من AWS RDS لحفظ أحدث لقطة من جداول Postgres في S3. ثم نقوم بإنشاء مهمة Spark لقراءة تلك البيانات من S3 وكتابتها في تنسيق جدول Hudi.أخيراً، نتأكد من أن جميع التغييرات التي تم إجراؤها خلال عملية التقاط الصورة تم التقاطها من خلال إعداد Deltastreamer لقراءة رسائل Kafka من
t. هذه الخطوة حاسمة للحفاظ على اكتمال البيانات وسلامتها.
بفضل قابلية التوسع في Spark وHudi، عادةً ما تكتمل هذه الخطوات الثلاث في غضون 24 ساعة، مما يسمح لنا بإجراء إعادة تمهيد مع وقت قابل للإدارة لاستيعاب طلبات الجدول الجديدة وترقية Postgres وعمليات إعادة تقسيم البيانات.
العائد: أقل تكلفة، المزيد من الوقت، بنية تحتية أقوى للذكاء الاصطناعي.
بدأنا في تطوير بنية تحتية لبحيرة البيانات الخاصة بنا في ربيع عام 2022 وأكملناها بحلول ذلك الخريف. نظراً للطبيعة القابلة للتوسع للبنية التحتية، تمكنا من تحسين وتوسيع مجموعات Debezium EKS، ومجموعات Kafka، وDeltastreamer، ومهمة Spark باستمرار لمواكبة معدل تضاعف البيانات في Notion الذي يتراوح بين 6 إلى 12 شهراً دون الحاجة إلى تغييرات كبيرة. كان العائد كبيراً:
نقل عدة مجموعات بيانات Postgres الكبيرة والحاسمة (بعضها بحجم عشرات التيرابايت) إلى بحيرة البيانات منحنا توفيراً صافياً يزيد عن مليون دولار لعام 2022 وتوفيراً أعلى بشكل متناسب في 2023 و2024.
بالنسبة لهذه المجموعات، انخفض وقت الإدخال من Postgres إلى S3 وSnowflake من أكثر من يوم إلى بضع دقائق للجداول الصغيرة وما يصل إلى بضع ساعات للجداول الكبيرة. يمكن إكمال إعادة المزامنة، عند الضرورة، في غضون 24 ساعة دون تحميل قواعد البيانات الحية.
الأهم من ذلك، أن التحول أطلق العنان لتوفير هائل في تخزين البيانات، والحوسبة، والانتعاش من مجموعة متنوعة من طلبات التحليلات والمنتجات، مما مكن من طرح ميزات Notion AI بنجاح في 2023 و2024. تابعونا للحصول على منشور مفصل حول بنية البحث ودمج الذكاء الاصطناعي RAG التي تم بناؤها على قمة بحيرة البيانات!
نود أن نشكر OneHouse ومجتمع Hudi مفتوح المصدر على دعمهم الهائل وفي الوقت المناسب. كان الدعم الرائع من المصادر المفتوحة حاسماً لقدرتنا على إنشاء بحيرة البيانات في غضون بضعة أشهر.
مع تزايد احتياجاتنا وتنوعها، نستمر في تعزيز بحيرة البيانات الخاصة بنا من خلال بناء أطر عمل آلية وخدمة ذاتية لتمكين المزيد من المهندسين من إدارة وتطوير حالات استخدام المنتج بناءً على البيانات.
هل ترغب في مساعدتنا في بناء الجيل التالي من إدارة بيانات Notion؟ قدّم طلباً لوظائفنا المفتوحة هنا.
