ההקמה וההרחבה של אגם הנתונים של Notion

על ידי XZ Tie, Nathan Louie, Thomas Chow, Darin Im, Abhishek Modi, Wendy Jiao
בשלוש השנים האחרונות, כמות הנתונים של Notion גדלה פי 10 עקב גידול במספר המשתמשים ובכמות התכנים, עם קצב הכפלה של 6-12 חודשים. ניהול הצמיחה המהירה הזו תוך מתן מענה לדרישות הנתונים ההולכות וגדלות של מקרי שימוש קריטיים במוצר ובניתוח הנתונים, במיוחד התכונות החדשות של Notion AI, חייבו את ההקמה וההרחבה של אגם הנתונים של Notion. כך עשינו זאת.
מודל הנתונים והצמיחה של Notion
כל מה שאתם רואים ב-Notion – טקסטים, תמונות, כותרות, רשימות, שורות מאגר ידע, דפים ועוד – למרות השוני בייצוג ובהתנהגות בצד הלקוח (Front-end), מופיע כישות 'בלוק' בצד השרת (Back-end) ומאוחסן במסד הנתונים Postgres עם מבנה, סכימה ומטא-נתונים קשורים עקביים (למידע נוסף על מודל הנתונים של Notion).
כל נתוני הבלוק הללו הוכפלו כל 6 עד 12 חודשים, כתוצאה מפעילות המשתמשים ומהתוכן שהם יצרו. בתחילת 2021 היו לנו יותר מ-20 מיליארד שורות בלוק ב-Postgres, ומאז המספר הזה גדל ליותר מ-200 מיליארד בלוקים – נפח נתונים של מאות טרה-בייט, גם לאחר דחיסה.
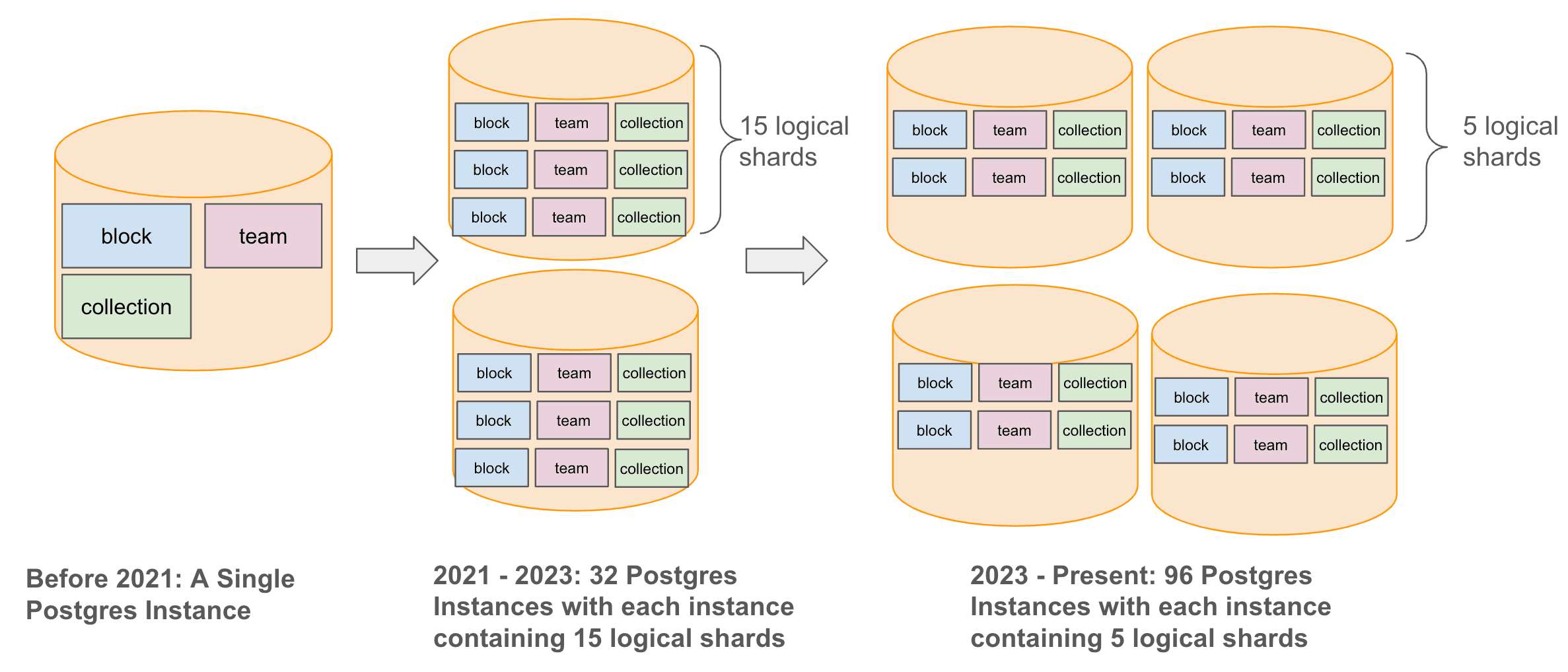
כדי לנהל את הגידול בכמות הנתונים תוך שיפור חוויית המשתמשים, הרחבנו באופן אסטרטגי את תשתית מסד הנתונים שלנו ממופע Postgres אחד לארכיטקטורה משולבת ומורכבת יותר. התחלנו בשנת 2021 בחלוקה (Sharding) רוחבית של מסד הנתונים Postgres ל-32 מופעים פיזיים, שכל אחד מהם כלל 15 שברים (Shards) לוגיים, והמשכנו בשנת 2023 בהגדלת מספר המופעים הפיזיים ל-96, עם חמישה שברים לוגיים לכל מופע. כך שמרנו על סך של 480 שברים לוגיים, תוך הבטחת יכולות ניהול ואחזור נתונים הניתנות להרחבה לטווח ארוך.
עד 2021, מסד הנתונים Postgres היווה את הליבה של תשתית הייצור שלנו וטיפל בכל דבר, החל מתעבורת משתמשים מקוונת ועד לצרכים שונים של ניתוח נתונים לא מקוונים ולמידת מכונה. עם העלייה בביקוש לנתונים מקוונים ולא מקוונים, הבנו שיש צורך לבנות תשתית נתונים ייעודית לטיפול בנתונים לא מקוונים, בלי לפגוע בתעבורה המקוונת.
ארכיטקטורת מחסן הנתונים של Notion ב-2021
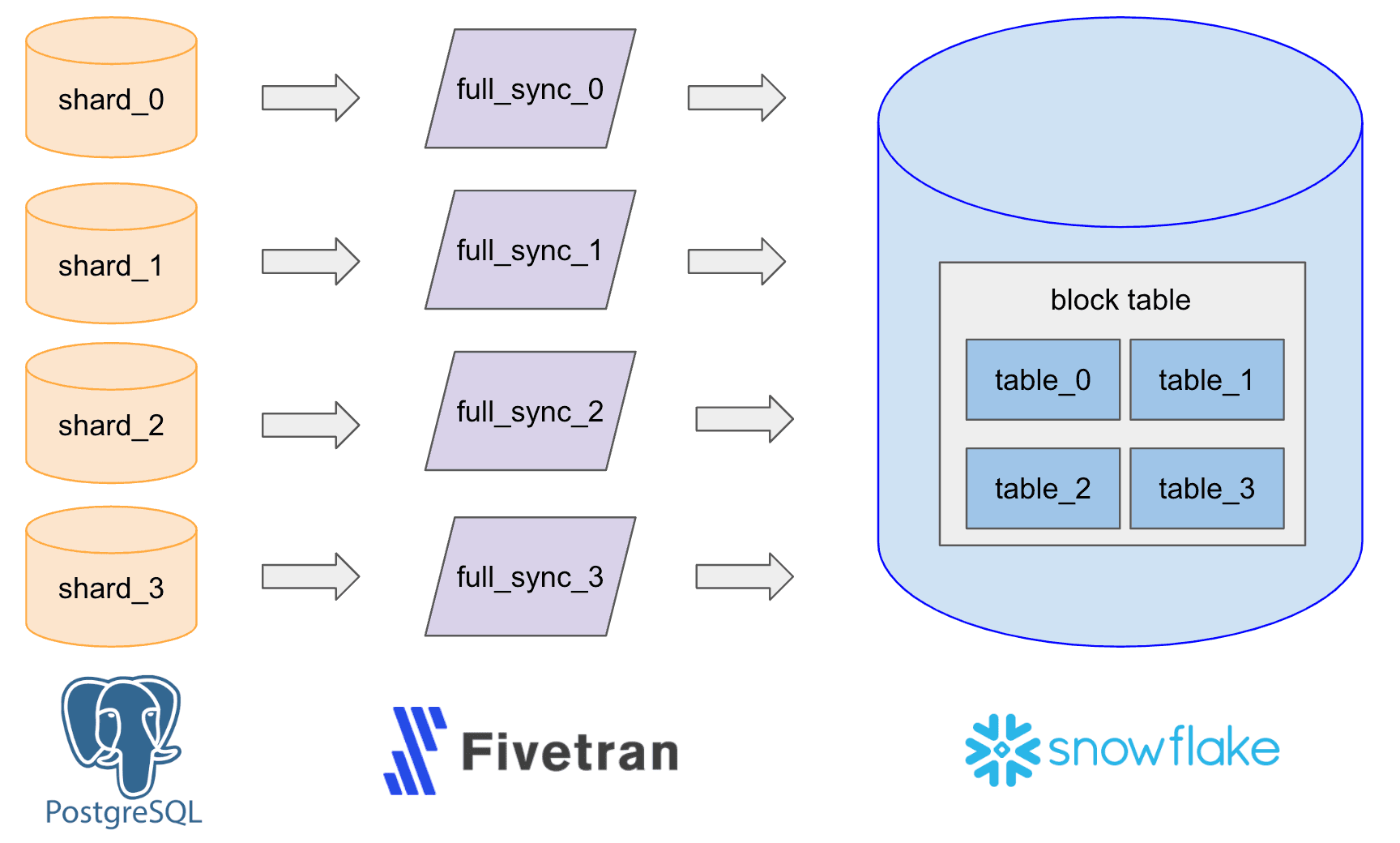
בשנת 2021, הקמנו את תשתית הנתונים הייעודית הזו באמצעות צינור נתונים פשוט (Extract, Load ו-Transform, או בקיצור ELT), שהשתמש בכלי צד שלישי בשם Fivetran כדי לקלוט נתונים מה-WAL (Write Ahead Log) של Postgres ל-Snowflake ולהגדיר 480 מחברים הפועלים מדי שעה עבור 480 השברים, כדי לכתוב לאותו מספר של טבלאות Snowflake גולמיות. לאחר מכן איחדנו את הטבלאות הללו לטבלה אחת גדולה לצורך מקרי שימוש של ניתוח נתונים, דיווח ולמידת מכונה.
אתגרי ההרחבה
עם הגידול בכמות הנתונים ב-Postgres, נתקלנו בכמה אתגרים בהרחבת המאגר.
תפעוליות
התקורה הכרוכה בניטור ובניהול של 480 מחברי Fivetran, יחד עם סנכרון מחדש שלהם במהלך תקופות של חלוקה מחדש (Re-sharding), שדרוג ותחזוקה של Postgres, הפכה להיות גבוהה ביותר ויצרה עומס משמעותי לחברי הצוות.
מהירות, עדכניות הנתונים ועלות
קליטת הנתונים ב-Snowflake נעשתה איטית ויקרה יותר, בעיקר בשל עומס העבודה הייחודי של Notion, המאופיין בעדכונים מרובים. משתמשי Notion מעדכנים בלוקים קיימים (טקסטים, כותרות, רשימות תבליטים, שורות מאגר ידע ועוד) בתדירות גבוהה הרבה יותר מזו שבה הם מוסיפים בלוקים חדשים. כתוצאה מכך, נתוני הבלוקים מצריכים עדכונים מרובים ביותר – 90% מפעולות ה-Upsert ב-Notion הן עדכונים. רוב מחסני הנתונים, כולל Snowflake, מותאמים לעומסי עבודה של הוספות מרובות, מה שמקשה עליהם יותר ויותר לקלוט נתוני בלוקים.
תמיכה במקרי שימוש
לוגיקת המרת הנתונים הפכה למורכבת וכבדה יותר, וחצתה את היכולות של ממשק ה-SQL הסטנדרטי שמוצע על ידי מחסני הנתונים הנפוצים.
מקרה שימוש חשוב אחד הוא בניית תצוגות לא מנורמלות (Denormalized) של נתוני הבלוקים של Notion עבור מוצרים מרכזיים (למשל, AI וחיפוש). נתוני הרשאות, למשל, מבטיחים שרק האנשים הנכונים יוכלו לקרוא או לשנות בלוק (הבלוג הזה דן במודל הרשאות הבלוק של Notion). אבל ההרשאה של בלוק אינה מאוחסנת באופן סטטי ב-Postgres המשויך – היא חייבת להיבנות בזמן אמת באמצעות חישוב יקר של סריקת עץ.
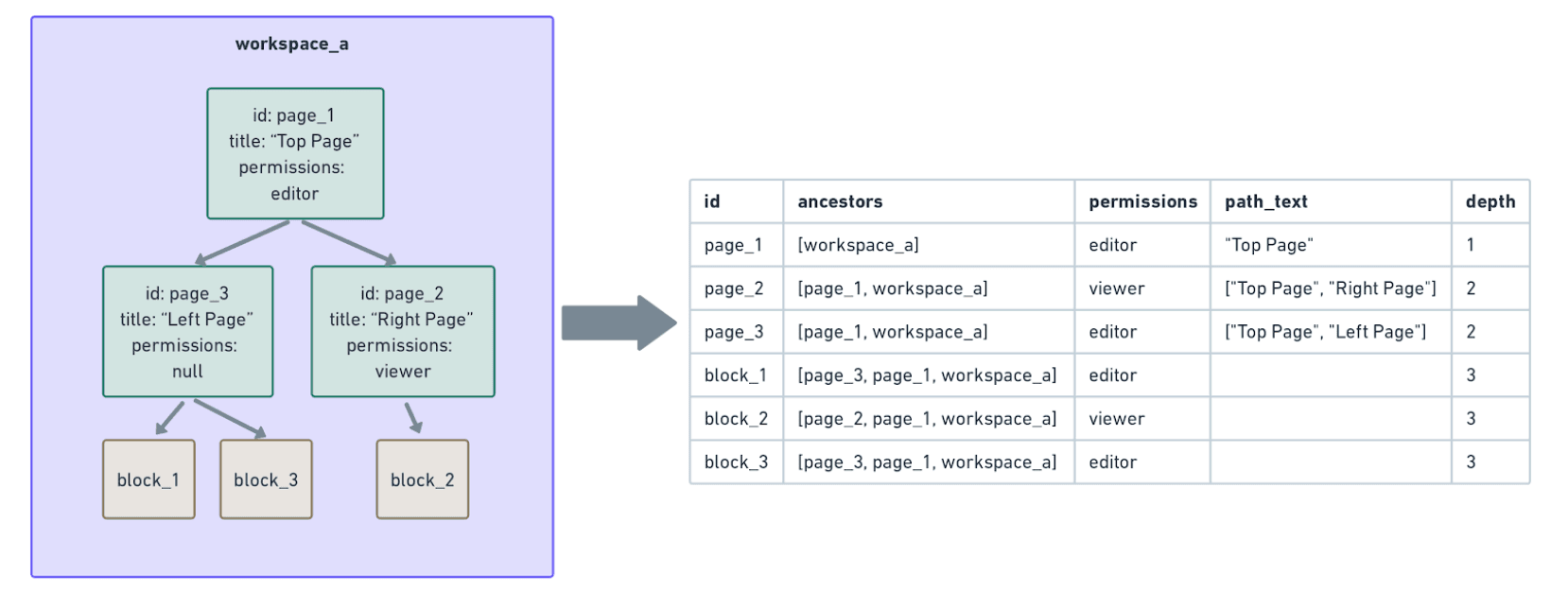
בדוגמה הבאה,
block_1,block_2ו-block_3 יורשיםהרשאות מההורים הישירים שלהם (page_3ו-page_2) ומהאבות שלהם (page_1ו-workspace_a).כדי לבנות נתוני הרשאה עבור כל אחד מהבלוקים הללו, עלינו לסרוק את עץ האבות שלו עד לשורש (workspace_a) כדי להבטיח שלמות. עם מאות מיליארדי בלוקים שעומק האבות שלהם נע בין כמה בודדים לעשרות, חישוב מסוג זה היה יקר מאוד ופשוט לא עמד במגבלות הזמן ב-Snowflake.
בגלל האתגרים הללו, התחלנו לבחון את האפשרות להקים אגם נתונים.
ההקמה וההרחבה של אגם הנתונים הפנימי של Notion
אלה היו היעדים שלנו בבניית מאגר נתונים פנימי:
להקים מאגר נתונים המסוגל לאחסן נתונים גולמיים ומעובדים בקנה מידה גדול.
לאפשר קליטה ועיבוד של נתונים באופן מהיר, ניתן להרחבה, ישים וחסכוני עבור כל עומס עבודה – במיוחד נתוני בלוקים של Notion המתאפיינים בעדכונים מרובים.
לאפשר AI, חיפוש ומקרי שימוש אחרים במוצר הדורשים נתונים לא מנורמלים.
עם זאת, למרות שאגם הנתונים שלנו מהווה צעד גדול קדימה, חשוב להבהיר מה הוא לא נועד לעשות:
להחליף לגמרי את Snowflake. נמשיך ליהנות מהקלות התפעולית ומהאקוסיסטם של Snowflake בכך שנשתמש בו עבור מרבית עומסי העבודה האחרים, במיוחד אלה הכרוכים בהוספות נתונים מרובות ואינם דורשים סריקת עץ לא מנורמל בקנה מידה גדול.
להחליף לגמרי את Fivetran. נמשיך לנצל את היעילות של Fivetran עם טבלאות שאינן דורשות עדכונים מרובים, עם מערכי נתונים קטנים ועם מגוון מקורות נתונים ויעדים של צד שלישי.
לתמוך במקרי שימוש מקוונים הדורשים זמן השהיה ברמה שנייה או חמורה יותר. אגם הנתונים של Notion יתמקד בעיקר בעומסי עבודה לא מקוונים שיכולים לסבול זמן השהיה של דקות עד שעות.
העיצוב הכולל של אגם הנתונים שלנו
מאז 2022 אנו משתמשים בארכיטקטורת אגם הנתונים הפנימית המוצגת למטה. אנו קולטים נתונים שמתעדכנים בהדרגה מ-Postgres ל-Kafka באמצעות מחברי Debezium CDC, ולאחר מכן משתמשים ב-Apache Hudi, מסגרת קוד פתוח לעיבוד ואחסון נתונים, כדי לכתוב את העדכונים האלה מ-Kafka ל-S3. בעזרת נתונים גולמיים אלה, אנו יכולים לבצע טרנספורמציה, דה-נורמליזציה (לדוגמה, סריקת עץ ובניית נתוני הרשאות עבור כל בלוק) והעשרה, ולאחר מכן לאחסן את הנתונים המעובדים שוב ב-S3 או במערכות Downstream כדי לענות על צורכי ניתוח ודיווח, כמו גם על דרישות AI, חיפוש ודרישות מוצר אחרות.
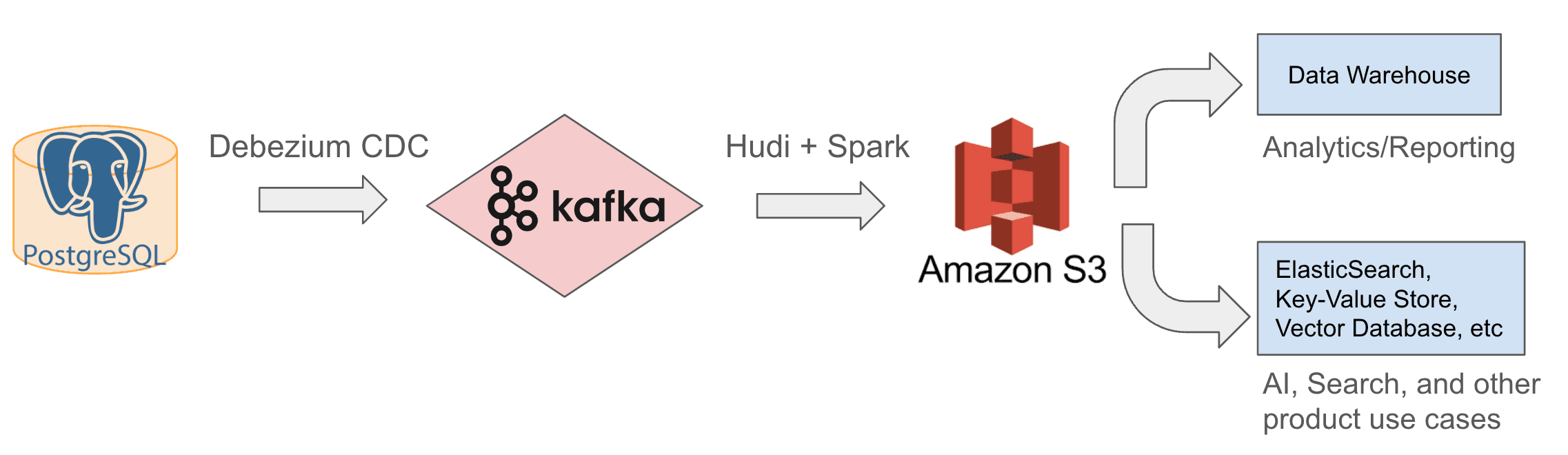
בהמשך נתאר ונמחיש את עקרונות העיצוב וההחלטות שקיבלנו לאחר עבודה מתמשכת של מחקר, דיונים ויצירת אב טיפוס.
החלטה עיצובית 1: בחירת מאגר נתונים ואגם נתונים
ההחלטה הראשונה שלנו הייתה להשתמש ב-S3 כמאגר נתונים וכאגם נתונים לאחסון כל הנתונים הגולמיים והמעובדים, ולמקם את מחסן הנתונים ואת מאגרי הנתונים האחרים הפונים למוצרים (Product-facing), כגון ElasticSearch, Vector Database, מאגר Key-Value ועוד כ-Downstream שלו. קיבלנו החלטה זו משתי סיבות:
זה עלה בקנה אחד עם מחסן הטכנולוגיות (tech stack) של Notion ב-AWS. לדוגמה, מסד הנתונים Postgres שלנו מבוסס על AWS RDS, ותכונת ה'ייצוא ל-S3' שלו (שתתואר בהמשך) מאפשרת לנו לבצע בוטסטראפ (Bootstrap) לטבלאות ב-S3 בקלות.
S3 הוכיח את יכולתו לאחסן כמויות גדולות של נתונים ולתמוך במנועי עיבוד נתונים שונים (כמו Spark) בעלות נמוכה.
בזכות זה שהעברנו עומסי קליטה וחישוב כבדים אל S3, והחלטנו לקלוט ב-Snowflake ובמאגרי נתונים הפונים למוצר (product-facing) רק נתונים נקיים ביותר הקריטיים לצרכים עסקיים, שיפרנו משמעותית את המהירות ואת יכולת ההרחבה (scalability) של החישוב והפחתנו עלויות.
החלטה עיצובית 2: בחירת מנוע העיבוד שלנו
בחרנו ב-Spark כמנוע עיבוד הנתונים העיקרי שלנו מכיוון שמסגרת הקוד הפתוח שלו מאפשרת להגדיר ולבדוק אותו במהירות כדי לוודא שהוא עונה על צורכי טרנספורמציית הנתונים שלנו. ל-Spark ארבעה יתרונות עיקריים:
מגוון רחב של פונקציות מובנות ופונקציות UDF (פונקציות המוגדרות על ידי המשתמשים) מעבר ל-SQL מאפשרות ל-Spark לבצע לוגיקות עיבוד נתונים מורכבות, כגון סריקת עץ ודה-נורמליזציה של נתוני בלוקים, כפי שתואר למעלה.
הוא מציע מסגרת PySpark ידידותית למשתמשים עבור רוב מקרי השימוש הקלים יותר, ומסגרת Scala Spark מתקדמת לעיבוד נתונים בכמויות גדולות שמצריך ביצועים גבוהים.
הוא מעבד נתונים בקנה מידה גדול (למשל, מיליארדי בלוקים ומאות טרה-בייט) באופן מבוזר, וחושף מגוון רחב של תצורות, וכך מאפשר לנו לכוונן את השליטה שלנו על חלוקה למחיצות, הטיית נתונים והקצאת משאבים. הוא גם מאפשר לנו לפצל משימות מורכבות למשימות קטנות יותר ולבצע אופטימיזציה של המשאבים עבור כל משימה, מה שעוזר לנו להשיג זמן ריצה סביר ללא הקצאת יתר או בזבוז משאבים.
דבר אחרון, מסגרת הקוד הפתוח של Spark מציעה יתרונות של עלות-תועלת.
החלטה עיצובית 3: העדפת קליטה הדרגתית על פני העתקה מלאה של תמונת מצב
אחרי שסיימנו לפתח את מנוע האחסון והעיבוד של אגם הנתונים שלנו, חיפשנו פתרונות לקליטת נתוני Postgres ב-S3. בסופו של דבר שקלנו שתי גישות: קליטה הדרגתית של נתונים שהשתנו לעומת העתקה מלאה של תמונת מצב תקופתית של טבלאות Postgres. בסופו של דבר, לאחר השוואת ביצועים ועלויות, בחרנו בעיצוב היברידי:
במהלך פעילות רגילה, המערכת קולטת נתונים באופן הדרגתי ומיישמת באופן רציף שינויים מ-Postgres ב-S3.
במקרים נדירים, המערכת יוצרת תמונת מצב מלאה של Postgres פעם אחת כדי לבצע בוטסטראפ (bootstrap) לטבלאות ב-S3.
הגישה ההדרגתית מבטיחה נתונים עדכניים יותר בעלות נמוכה יותר ועם עיכוב מינימלי (כמה דקות עד כמה שעות, בהתאם לגודל הטבלה). לעומת זאת, התהליך של יצירת תמונת מצב מלאה והעתקתה ל-S3 אורך יותר מ-10 שעות ועולה פי שניים, ולכן אנו עושים זאת לעיתים רחוקות, כאשר אנו מבצעים בוטסטראפ לטבלאות חדשות ב-S3.
החלטה עיצובית 4: ייעול הקליטה ההדרגתית
מחבר Kafka CDC עבור Postgres → אל → Kafka
בחרנו במחבר Kafka Debezium CDC (Change Data Capture) כדי לפרסם ב-Kafka באופן הדרגתי נתוני Postgres שהשתנו, בדומה לשיטת קליטת הנתונים של Fivetran. בחרנו בו יחד עם Kafka בשל יכולת ההרחבה, קלות ההתקנה והאינטגרציה ההדוקה עם התשתית הקיימת שלנו.
Hudi עבור Kafka → אל → S3
כדי לקלוט את הנתונים המצטברים מ-Kafka ב-S3, שקלנו שלושה פתרונות מצוינים של אגם נתונים וקליטת נתונים: Apache Hudi, Apache Icebergו-DataBricks Delta Lake. בסופו של דבר בחרנו ב-Hudi בזכות הביצועים המעולים שלו עם עומס העבודה מרובה-העדכונים שלנו, מסגרת הקוד הפתוח שלו והאינטגרציה המקורית שלו עם הודעות Debezium CDC.
לעומת זאת, Iceberg ו-Delta Lake לא התאימו באופן מיטבי לעומס העבודה מרובה-העדכונים שלנו כאשר שקלנו אותם בשנת 2022. Iceberg גם לא הציע פתרון מוכן לשימוש שמבין הודעות Debezium; ל-Delta Lake יש פתרון כזה, אך הוא אינו קוד פתוח. אילו בחרנו באחד מהפתרונות הללו, היינו צריכים להטמיע צרכן Debezium משלנו.
החלטה עיצובית 5: קליטת נתונים גולמיים לפני העיבוד
בסופו של דבר, החלטנו לקלוט נתוני Postgres גולמיים ב-S3 ללא עיבוד בזמן אמת, כדי ליצור מקור מהימן יחיד ולפשט את פתרון הבאגים בכל צינור הנתונים. ברגע שהנתונים הגולמיים נמצאים ב-S3, אנו מבצעים טרנספורמציה, דה-נורמליזציה, העשרה וסוגים אחרים של עיבוד נתונים. אנו מאחסנים נתוני ביניים ב-S3 שוב, וקולטים במערכות ה-Downstream רק נתונים נקיים ביותר, מובנים וקריטיים לעסק בשביל ניתוח נתונים, דיווח וצורכי המוצר.
הרחבה ותפעול של אגם הנתונים שלנו
ניסינו הגדרות מפורטות רבות כדי להתמודד עם אתגרי הגדילה הקשורים לנפח הנתונים ההולך וגדל של Notion. אלה ההגדרות שניסינו ותהליכי הניסוי:
1. הגדרה של מחבר CDC ו-Kafka
הגדרנו מחבר Debezium CDC אחד לכל מארח Postgres ופרסנו אותם באשכול AWS EKS. בזכות הבשלות של Debezium וניהול ה-EKS, יחד עם יכולת ההרחבה (scalability) של Kafka, נדרשנו לשדרג את אשכולות ה-EKS וה-Kafka פעמים ספורות בלבד בשנתיים האחרונות. נכון למאי 2024, הוא מטפל בצורה חלקה בעשרות מגה-בייט לשנייה של שינויים בשורות Postgres.
אנו גם מגדירים נושא Kafka אחד לכל טבלת Postgres ומאפשרים לכל המחברים שצורכים מ-480 שברים לכתוב לאותו נושא עבור טבלה זו. הגדרה זו הפחיתה באופן משמעותי את המורכבות של תחזוקת 480 נושאים עבור כל טבלה ופישטה את קליטת Hudi ב-Downstream ב-S3, מה שהפחית באופן משמעותי את העלויות התפעוליות.
2. הגדרת Hudi
השתמשנו ב-Apache Hudi Deltastreamer, משימת קליטה מבוססת Spark, כדי לצרוך הודעות Kafka ולשכפל את המצב של טבלת Postgres ב-S3. לאחר כמה סבבים של כוונון ביצועים, הקמנו הגדרת קליטה מהירה וניתנת להרחבה כדי להבטיח את עדכניות הנתונים. הגדרה זו מספקת עיכוב של כמה דקות בלבד עבור רוב הטבלאות, ועד שעתיים עבור הטבלה הגדולה ביותר, טבלת הבלוקים (ראו תרשים למטה).
אנו משתמשים בסוג הטבלה COPY_ON_WRITE Hudi המוגדר כברירת מחדל עם פעולת UPSERT, המתאימה לעומס העבודה מרובה העדכונים שלנו.
כדי לנהל את הנתונים בצורה יעילה יותר ולמזער את הגברת הכתיבה (כלומר, מספר הקבצים המעודכנים בכל הרצת קליטה של אצווה), ביצענו כוונון עדין של שלוש תצורות:
חלוקה למחיצות/פיצול של נתונים באמצעות אותה תבנית חלוקה של Postgres, כלומר, תצורת
hoodie.datasource.write.partitionpath.field: db_schema_source_partition. פעולה זו מחלקת את מערך הנתונים S3 ל-480 שברים,מ-shard0001עדshard0480,מה שמגדיל את הסבירות שאצוות עדכונים נכנסת תמופה לאותו מערך קבצים מאותו שבר.מיון נתונים על פי זמן העדכון האחרון (event_lsn), כלומר, תצורת
source-ordering-field: event_lsn. זאת בהתבסס על ההבחנה שלנו שבלוקים חדשים יותר נוטים יותר להתעדכן, מה שמאפשר לנו לגזום קבצים עם בלוקים מיושנים בלבד.הגדרת סוג האינדקס כמסנן Bloom, כלומר, תצורת
hoodie.index.type: BLOOM, כדי לייעל עוד יותר את עומס העבודה.

3. הגדרת עיבוד נתונים ב-Spark
ברוב משימות עיבוד הנתונים שלנו אנו משתמשים ב-PySpark, שבזכות עקומת הלמידה הנמוכה יחסית שלו נגיש לרבים מחברי הצוות. למשימות מורכבות יותר, כגון סריקה ודה-נורמליזציה של עץ, אנו מנצלים את הביצועים המעולים של Spark בכמה תחומים מרכזיים:
אנו נהנים מיעילות הביצועים של Scala Spark.
אנו מנהלים את הנתונים בצורה יעילה יותר על ידי טיפול בשברים קטנים וגדולים בנפרד (זכרו ששמרנו על אותה תבנית של 480 שברים ב-S3 כדי לשמור על עקביות עם Postgres); הנתונים של שברים קטנים נטענים במלואם בזיכרון ה-Container של משימת ה-Spark לצורך עיבוד מהיר, בעוד ששברים גדולים החורגים מקיבולת הזיכרון מנוהלים על ידי ארגון מחדש של הנתונים בדיסק (disk reshuffling).
אנו משתמשים בריבוי תהליכים ובעיבוד מקביל כדי להאיץ את עיבוד 480 השברים, וזה מאפשר לנו לשפר את זמן הריצה ולהגביר את היעילות.
4. הגדרת בוטסטראפ (Bootstrap)
כך אנו מבצעים בוטסטראפ לטבלאות חדשות:
ראשית, הגדרנו את Debezium Connector כדי לקלוט שינויים ב-Postgres ב-Kafka.
החל מנקודת הזמן
t, אנו מפעילים משימת ייצוא ל-S3 שמסופקת על ידי AWS RDS כדי לשמור את תמונת המצב העדכנית ביותר של טבלאות Postgres ב-S3. לאחר מכן, אנו יוצרים משימת Spark כדי לקרוא את הנתונים הללו מ-S3 ולכתוב אותם בפורמט של טבלת Hudi.בשלב האחרון, אנו מוודאים שכל השינויים שבוצעו בתהליך היצירה של תמונת המצב יתועדו על ידי הגדרת Deltastreamer לקריאה מהודעות Kafka מנקודת הזמן
t. שלב זה הוא חיוני לשמירה על שלמות הנתונים ועל תקינותם.
בזכות יכולת ההרחבה (scalability) של Spark ושל Hudi, שלושת השלבים הללו מסתיימים בדרך כלל בתוך 24 שעות. זה מאפשר לנו לבצע אכלוס מחדש (re-bootstrap) בפרק זמן סביר, כדי לתת מענה לבקשות לטבלאות חדשות וכן לפעולות שדרוג וחלוקה מחדש (re-sharding) של ה-Postgres.
התמורה: פחות כסף, יותר זמן, תשתית חזקה יותר עבור AI
התחלנו לפתח את תשתית אגם הנתונים שלנו באביב 2022 והשלמנו אותה בסתיו של אותה שנה. בזכות האופי המדרגי המובנה של התשתית, הצלחנו לייעל ולהרחיב באופן רציף את אשכולות Debezium EKS, אשכולות Kafka, Deltastreamer ומשימת Spark כדי לעמוד בקצב הכפלת הנתונים של Notion, העומד על 6 עד 12 חודשים, ללא צורך בשינויים נרחבים משמעותיים. התמורה הייתה משמעותית:
ההעברה של מספר מערכי נתונים גדולים וחשובים של Postgres (חלקם בגודל של עשרות טרה-בייט) לאגם נתונים העניקה לנו חיסכון נטו של למעלה ממיליון דולר לשנת 2022, וחיסכון גבוה יותר באופן יחסי בשנים 2023 ו-2024.
עבור מערכי נתונים אלה, זמן הקליטה מקצה לקצה מ-Postgres ל-S3 ו-Snowflake ירד מפרק זמן של יותר מיום לכמה דקות בלבד עבור טבלאות קטנות, ועד כמה שעות עבור טבלאות גדולות. סנכרונים מחדש, בעת הצורך, יכולים להתבצע תוך 24 שעות מבלי להעמיס על מסדי הנתונים הפעילים.
וחשוב מכול, המעבר הוביל לחיסכון עצום באחסון נתונים, במשאבי מחשוב ובעדכניות הנתונים עבור מגוון דרישות של ניתוח נתונים ושל המוצרים השונים, וכך התאפשרה ההשקה המוצלחת של תכונות Notion AI בשנים 2023 ו-2024. כדאי להמשיך לעקוב – בהמשך יעלה פוסט מפורט על תשתית RAG לחיפוש ולהטמעת בינה מלאכותית, המבוססת על אגם הנתונים!
אנו רוצים להודות ל-OneHouse ולקהילת הקוד הפתוח Hudi על תמיכתם העצומה שניתנה בדיוק בזמן. בזכות התמיכה המעולה בקוד פתוח הצלחנו להקים את אגם הנתונים בתוך חודשים ספורים בלבד.
ככל שהצרכים שלנו גדלים ונעשים מגוונים יותר, אנו ממשיכים לשפר את אגם הנתונים שלנו על ידי בניית מסגרות אוטומטיות ובשירות עצמי, כדי לאפשר ליותר מהנדסים לנהל ולפתח מקרי שימוש במוצרים על בסיס הנתונים.
רוצים לעזור לנו לבנות את הדור הבא של ניהול הנתונים של Notion? אתם מוזמנים להגיש מועמדות למשרות הפנויות שלנו כאן.
